News Message
MIT 新研究 矩阵乘法无需相乘,速度提升100倍
- by wittx 2021-09-04
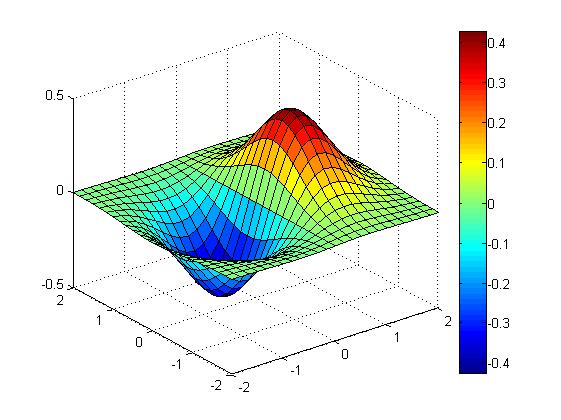
矩阵乘法是机器学习中最基础和计算密集型的操作之一。因此,研究社区在高效逼近矩阵乘法方面已经做了大量工作,比如实现高速矩阵乘法库、设计自定义硬件加速特定矩阵的乘法运算、计算分布式矩阵乘法以及在各种假设下设计高效逼近矩阵乘法(AMM)等。
在 MIT 计算机科学博士生 Davis Blalock 及其导师 John Guttag 教授发表的论文《 Multiplying Matrices Without Multiplying 》中,他们为逼近矩阵乘法任务引入了一种基于学习的算法,结果显示该算法显著优于现有方法。在来自不同领域的数百个矩阵的实验中,这种学习算法的运行速度是精确矩阵乘积的 100 倍,是当前近似方法的 10 倍。这篇论文入选了机器学习顶会 ICML 2021。
此外,在一个矩阵提前已知的常见情况下,研究者提出的方法还具有一个有趣的特性——需要的乘加运算(multiply-adds)为零。
这些结果表明,相较于最近重点进行了大量研究与硬件投入的稀疏化、因式分解和 / 或标量量化矩阵乘积而言,研究者所提方法中的核心操作——哈希、求平均值和 byte shuffling 结合可能是更有前途的机器学习构建块。

论文链接:https://arxiv.org/abs/2106.10860
代码链接:https://github.com/dblalock/bolt





一个高效的学习矢量量化函数族,可以在单个 CPU 线程中每秒编码超过 100GB 的数据。
一种用于低位宽整数( low-bitwidth integers)的高速求和算法,可避免 upcasting、饱和和溢出。
基于这些函数的近似矩阵乘法算法。数百个不同矩阵的实验表明,该算法明显优于现有替代方案。并且还具有理论质量保证。





Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=821


Best Last Month
Information industry
by wittx
Information industry
by wittx
Information industry
by wittx
Information industry
by wittx
Information industry
by wittx
Computer software and hardware
by wittx

Information industry
by wittx

Information industry
by wittx

Information industry
by wittx

Mechanical electromechanical
by wittx