News Message
强化学习 10:Actor-Critic、DDPG及A3C算法
- by wittx 2022-12-21
参考资料
[2]shura_R:【强化学习】Actor-Critic算法详解
[3]Quantum cheese:深度强化学习 -- Actor-Critic 类算法(基础篇)
[5]刘建平:强化学习(十六) 深度确定性策略梯度(DDPG)
1 Actor-Critic算法
1.1 Actor和Critic
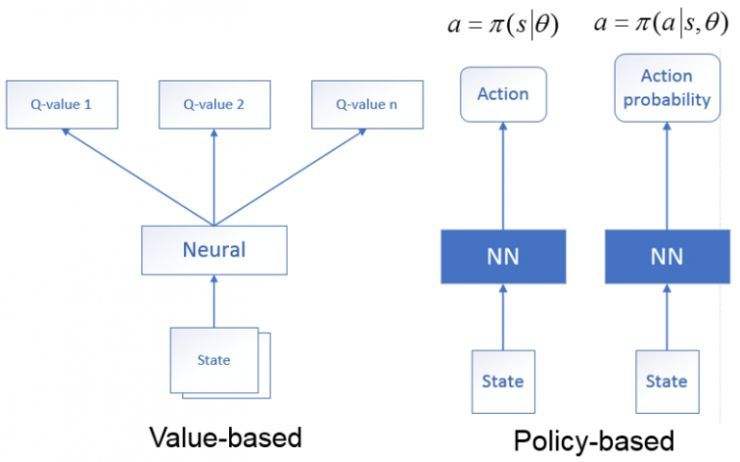
该算法使用拟合策略函数的神经网络作为 Actor,使用拟合状态值函数的神经网络作为 Critic。因此,Actor 是 Policy Based 算法,可以轻松地在连续动作空间内选择合适的动作;Critic 是 Value Based 算法,可以实现单步或多步更新,不需要经历完整的回合才更新。
Critic通过Q网络来计算状态的最优价值(评估点不一定要,也可以是状态价值、动作价值、TD误差等);Actor利用迭代更新策略函数的参数,然后选择动作;执行动作进入下一个状态,并得到reward;Critic利用reward和新状态更新Q网络参数,更新后再计算最优价值。
简单来说,就是Actor 基于概率选动作,Critic 基于 Actor 的动作评判动作的得分,Actor 根据 Critic 的评分修改选动作的概率。

在Actor中,策略函数的近似如下:
在Critic中,价值函数的近似如下:

Actor-Critic算法伪代码 但基础版的Actor-Critic算法由于使用两个神经网络,都需要梯度更新且相互依赖,因此难以收敛。
在此基础上,DDPG算法和A3C算法都进行了改进。
DDPG算法,使用了双Actor神经网络和双Critic神经网络的方法来改善收敛性。这个方法在从DQN到Nature DQN的过程中已经用过。
A3C算法,使用了多线程的方式,一个主线程负责更新Actor和Critic的参数,多个辅线程负责分别和环境交互,得到梯度更新值,汇总更新主线程的参数。而所有的辅线程会定期从主线程更新网络参数。这些辅线程起到了类似DQN中经验回放的作用,但是效果更好。
1.2 Critic评估点
在上面,我们提到了Critic评估点的选择。在上一篇笔记中,蒙特卡洛策略梯度使用价值函数来近似代替策略梯度公式里面的,参与对策略函数参数的更新。在AC算法中,也可以用价值函数作为Critic评估点,来判断Actor执行动作的得分。
除此之外,目前可以使用的Critic评估点主要有:(截自[4])

2 DDPG(Deep Deterministic Policy Gradient)算法
2.1 随机策略和确定性策略
中文翻译DDPG是深度确定性策略梯度。
策略梯度是Policy Based的经典算法,但被我略过了。
有确定性策略,就有随机策略。
随机策略在同一的策略、同一状态,采用的动作是基于一个概率分布的,是不确定的。而确定性策略在同一状态采用的动作是唯一确定的。
2.2 确定性策略梯度DPG
基于Q值的随机性策略梯度的梯度计算公式:
上式中,是状态的采样空间,是Score function,可见随机性策略梯度需要在整个动作的空间进行采样。
而DPG基于Q值的确定性策略梯度的梯度计算公式:
跟随机策略梯度的式子相比,少了对动作的积分,多了回报Q函数对动作的导数。
2.3 DDPG的原理
DDPG有4个网络:Actor当前网络,Actor目标网络,Critic当前网络,Critic目标网络。2个Actor网络的结构相同,2个Critic网络的结构相同。
DDQN的当前Q网络负责对当前状态使用ϵ−贪婪法选择动作,执行动作,获得新状态和奖励,将样本放入经验回放池,对经验回放池中采样的下一状态使用贪婪法选择动作,供目标Q网络计算目标Q值,当目标Q网络计算出目标Q值后,当前Q网络会进行网络参数的更新,并定期把最新网络参数复制到目标Q网络。
类比DDQN,DDPG中的Critic当前网络,Critic目标网络和DDQN的当前Q网络,目标Q网络的功能定位基本类似。但在选择动作时无需贪婪策略,而用Actor当前网络完成。对经验回放池中采样的下一状态使用贪婪法选择动作,这部分工作由于用来估计目标Q值,因此可以放到Actor目标网络完成。
- Actor当前网络:负责策略网络参数的迭代更新,负责根据当前状态S选择当前动作,用于和环境交互生成、。
- Actor目标网络:负责根据经验回放池中采样的下一状态选择最优下一动作。网络参数定期从复制。
- Critic当前网络:负责价值网络参数w的迭代更新,负责计算负责计算当前Q值。
- Critic目标网络:负责计算目标Q值。网络参数w′定期从复制。
此外,DDPG将当前网络参数复制到目标网络的方式改变了。
在DQN中,我们是直接把将当前Q网络的参数复制到目标Q网络。
但DDPG参数每次只更新一点点:
同时,为了学习过程可以增加一些随机性,增加学习的覆盖,DDPG对选择出来的动作会增加一定的噪声,即最终和环境交互的动作的表达式是:
对于Critic当前网络,其损失函数和DQN是类似的,都是均方误差,即:
而对于Actor当前网络,由于是确定性策略,和PG不同,定义的损失梯度是:
算法流程,截自5:

3 A3C算法(Asynchronous Advantage Actor-critic)
相比Actor-Critic,A3C的优化主要有3点,分别是Critic评估点的优化、异步训练框架、网络结构优化。其中异步训练框架是最大的优化。
3.1 Critic评估点的优化——A2C算法(Advantage Actor-critic)
除了A3C算法,在前面还有个A2C算法,顾名思义是用优化函数来作为Critic评估点。
Actor网络的更新:
但是在实际操作中,一般用TD误差代替优势函数进行计算,因为TD误差是优势函数的无偏估计。
TD error: 。
其中 需要通过Critic网络来学习得到。
因此Actor网络的更新公式为:
Critic网络一般使用MSE(均方误差)损失函数来做迭代更新,均方误差损失函数: =

上面是A2C,在A3C中采样不是单步,而是N步。因此A3C中的优势函数表达为:
Actor网络更新变成了(加入了策略 的熵项,系数为 ):
3.2 异步训练框架
A3C算法在Actor Critic算法的基础上增加了经验回放技术,但是是改进版的。
由于回放池数据相关性太强,A3C利用多线程的方法,同时在多个线程里分别和环境进行交互学习,每个线程都把学习的成果汇总起来保存在一个公共的神经网络,并且定期从公共的神经网络拿出成果指导后面的学习交互,做到了异步并发的学习模型。
这个公共的神经网络包括Actor网络和Critic网络两部分的功能。下面有n个worker线程,每个线程里有和公共的神经网络一样的网络结构,每个线程会独立的和环境进行交互得到经验数据,这些线程之间互不干扰,独立运行。
每个线程和环境交互到一定量的数据后,就计算在自己线程里的神经网络损失函数的梯度,但是这些梯度并不更新自己线程里的神经网络,而是去更新公共的神经网络。也就是n个线程会独立的使用累积的梯度分别更新公共部分的神经网络模型参数。每隔一段时间,线程会将自己的神经网络的参数更新为公共神经网络的参数,进而指导后面的环境交互。
可见,公共部分的网络模型就是我们要学习的模型,而线程里的网络模型主要是用于和环境交互使用的,这些线程里的模型可以帮助线程更好的和环境交互,拿到高质量的数据帮助模型更快收敛。
3.3 网络结构优化
在Actor Critic算法中,我们用了Actor和Critic两个不同的网络。在A3C中,我们把两个网络(类似两个子网络)放在一起,输入状态后可以同时输出状态价值和策略。
A3C算法流程,截自6:

参考资料
[2]shura_R:【强化学习】Actor-Critic算法详解
[3]Quantum cheese:深度强化学习 -- Actor-Critic 类算法(基础篇)
[5]刘建平:强化学习(十六) 深度确定性策略梯度(DDPG)
1 Actor-Critic算法
1.1 Actor和Critic
该算法使用拟合策略函数的神经网络作为 Actor,使用拟合状态值函数的神经网络作为 Critic。因此,Actor 是 Policy Based 算法,可以轻松地在连续动作空间内选择合适的动作;Critic 是 Value Based 算法,可以实现单步或多步更新,不需要经历完整的回合才更新。
Critic通过Q网络来计算状态的最优价值(评估点不一定要,也可以是状态价值、动作价值、TD误差等);Actor利用迭代更新策略函数的参数,然后选择动作;执行动作进入下一个状态,并得到reward;Critic利用reward和新状态更新Q网络参数,更新后再计算最优价值。
简单来说,就是Actor 基于概率选动作,Critic 基于 Actor 的动作评判动作的得分,Actor 根据 Critic 的评分修改选动作的概率。
在Actor中,策略函数的近似如下:
在Critic中,价值函数的近似如下:
但基础版的Actor-Critic算法由于使用两个神经网络,都需要梯度更新且相互依赖,因此难以收敛。
在此基础上,DDPG算法和A3C算法都进行了改进。
DDPG算法,使用了双Actor神经网络和双Critic神经网络的方法来改善收敛性。这个方法在从DQN到Nature DQN的过程中已经用过。
A3C算法,使用了多线程的方式,一个主线程负责更新Actor和Critic的参数,多个辅线程负责分别和环境交互,得到梯度更新值,汇总更新主线程的参数。而所有的辅线程会定期从主线程更新网络参数。这些辅线程起到了类似DQN中经验回放的作用,但是效果更好。
1.2 Critic评估点
在上面,我们提到了Critic评估点的选择。在上一篇笔记中,蒙特卡洛策略梯度使用价值函数来近似代替策略梯度公式里面的,参与对策略函数参数的更新。在AC算法中,也可以用价值函数作为Critic评估点,来判断Actor执行动作的得分。
除此之外,目前可以使用的Critic评估点主要有:(截自[4])
2 DDPG(Deep Deterministic Policy Gradient)算法
2.1 随机策略和确定性策略
中文翻译DDPG是深度确定性策略梯度。
策略梯度是Policy Based的经典算法,但被我略过了。
有确定性策略,就有随机策略。
随机策略在同一的策略、同一状态,采用的动作是基于一个概率分布的,是不确定的。而确定性策略在同一状态采用的动作是唯一确定的。
2.2 确定性策略梯度DPG
基于Q值的随机性策略梯度的梯度计算公式:
上式中,是状态的采样空间,是Score function,可见随机性策略梯度需要在整个动作的空间进行采样。
而DPG基于Q值的确定性策略梯度的梯度计算公式:
跟随机策略梯度的式子相比,少了对动作的积分,多了回报Q函数对动作的导数。
2.3 DDPG的原理
DDPG有4个网络:Actor当前网络,Actor目标网络,Critic当前网络,Critic目标网络。2个Actor网络的结构相同,2个Critic网络的结构相同。
DDQN的当前Q网络负责对当前状态使用ϵ−贪婪法选择动作,执行动作,获得新状态和奖励,将样本放入经验回放池,对经验回放池中采样的下一状态使用贪婪法选择动作,供目标Q网络计算目标Q值,当目标Q网络计算出目标Q值后,当前Q网络会进行网络参数的更新,并定期把最新网络参数复制到目标Q网络。
类比DDQN,DDPG中的Critic当前网络,Critic目标网络和DDQN的当前Q网络,目标Q网络的功能定位基本类似。但在选择动作时无需贪婪策略,而用Actor当前网络完成。对经验回放池中采样的下一状态使用贪婪法选择动作,这部分工作由于用来估计目标Q值,因此可以放到Actor目标网络完成。
- Actor当前网络:负责策略网络参数的迭代更新,负责根据当前状态S选择当前动作,用于和环境交互生成、。
- Actor目标网络:负责根据经验回放池中采样的下一状态选择最优下一动作。网络参数定期从复制。
- Critic当前网络:负责价值网络参数w的迭代更新,负责计算负责计算当前Q值。
- Critic目标网络:负责计算目标Q值。网络参数w′定期从复制。
此外,DDPG将当前网络参数复制到目标网络的方式改变了。
在DQN中,我们是直接把将当前Q网络的参数复制到目标Q网络。
但DDPG参数每次只更新一点点:
同时,为了学习过程可以增加一些随机性,增加学习的覆盖,DDPG对选择出来的动作会增加一定的噪声,即最终和环境交互的动作的表达式是:
对于Critic当前网络,其损失函数和DQN是类似的,都是均方误差,即:
而对于Actor当前网络,由于是确定性策略,和PG不同,定义的损失梯度是:
算法流程,截自5:
3 A3C算法(Asynchronous Advantage Actor-critic)
相比Actor-Critic,A3C的优化主要有3点,分别是Critic评估点的优化、异步训练框架、网络结构优化。其中异步训练框架是最大的优化。
3.1 Critic评估点的优化——A2C算法(Advantage Actor-critic)
除了A3C算法,在前面还有个A2C算法,顾名思义是用优化函数来作为Critic评估点。
Actor网络的更新:
但是在实际操作中,一般用TD误差代替优势函数进行计算,因为TD误差是优势函数的无偏估计。
TD error: 。
其中 需要通过Critic网络来学习得到。
因此Actor网络的更新公式为:
Critic网络一般使用MSE(均方误差)损失函数来做迭代更新,均方误差损失函数: =
上面是A2C,在A3C中采样不是单步,而是N步。因此A3C中的优势函数表达为:
Actor网络更新变成了(加入了策略 的熵项,系数为 ):
3.2 异步训练框架
A3C算法在Actor Critic算法的基础上增加了经验回放技术,但是是改进版的。
由于回放池数据相关性太强,A3C利用多线程的方法,同时在多个线程里分别和环境进行交互学习,每个线程都把学习的成果汇总起来保存在一个公共的神经网络,并且定期从公共的神经网络拿出成果指导后面的学习交互,做到了异步并发的学习模型。
这个公共的神经网络包括Actor网络和Critic网络两部分的功能。下面有n个worker线程,每个线程里有和公共的神经网络一样的网络结构,每个线程会独立的和环境进行交互得到经验数据,这些线程之间互不干扰,独立运行。
每个线程和环境交互到一定量的数据后,就计算在自己线程里的神经网络损失函数的梯度,但是这些梯度并不更新自己线程里的神经网络,而是去更新公共的神经网络。也就是n个线程会独立的使用累积的梯度分别更新公共部分的神经网络模型参数。每隔一段时间,线程会将自己的神经网络的参数更新为公共神经网络的参数,进而指导后面的环境交互。
可见,公共部分的网络模型就是我们要学习的模型,而线程里的网络模型主要是用于和环境交互使用的,这些线程里的模型可以帮助线程更好的和环境交互,拿到高质量的数据帮助模型更快收敛。
3.3 网络结构优化
在Actor Critic算法中,我们用了Actor和Critic两个不同的网络。在A3C中,我们把两个网络(类似两个子网络)放在一起,输入状态后可以同时输出状态价值和策略。
A3C算法流程,截自6:
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1066


Best Last Month

.jpg)
.jpg)

Robot Navigation among External Autonomous Agents through Deep Reinforcement learning using Graph At