News Message
DeepSeek强化学习的策略优化PPO, TRPO GRPO
- by wittx 2026-06-08
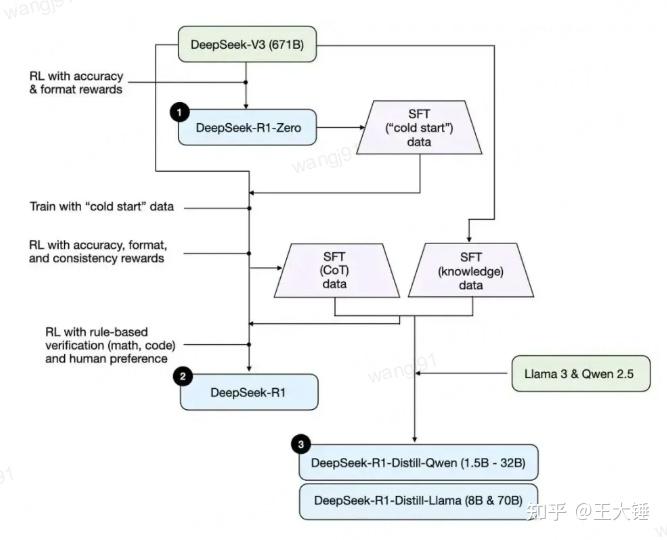
在本次模型发布中,DeepSeek共发布了三个系列的模型
- R1-Zero:仅通过RL进行训练,未进行SFT的强推理能力模型
- R1:通过融入冷启动数据与多阶段训练提升推理性能的模型
- R1-Distill:在R1基础上,基于Qwen/Llama蒸馏出的系列密集模型
其中一个核心的点就是强化学习的深度使用,在强化学习中,优化策略是一个非常重要的环节,在之前的大模型训练中PPO算法得到了广泛使用,而DeepSeek-R1则进一步使用了GRPO算法,所以本文以DeepSeek-R1为契机,对目前大模型中使用的策略进行总结,
一句话总结下,PPO、TRPO 和 GRPO的关系。PPO、TRPO 和 GRPO 都是用于优化强化学习策略的方法,其中 PPO 通过裁剪控制策略更新,TRPO 通过信赖域和 KL 散度约束保证稳定性,而 GRPO 结合了两者的优点,采用群体相对优势计算和自适应 KL 约束实现更高效的优化,进一步降低了计算复杂度和资源需求。
1. PPO(Proximal Policy Optimization):
1.1 PPO介绍
旨在优化策略网络以最大化累计奖励,同时限制新策略与旧策略之间的差异,确保训练过程的稳定性。它通过引入一个近端策略优化目标函数,使得策略更新能够在保证策略改进的同时,避免更新过大导致模型性能下降。PPO 算法在大模型训练中表现出了良好的性能和稳定性,能够有效地利用样本数据进行学习,适用于各种复杂的任务,如机器人控制、自动驾驶等领域的大模型训练。
其实在ChatGPT最初开源的一个训练流程把PPO policy展示了出来,在第三个环节,如下图:
PPO的核心公式如下所示,
1.2 PPO核心机制
关于PPO网络的核心机制下面是一个介绍,其中非常重要的一个环节是数据重要性采样、裁剪机制、
(1) 重要性采样(Importance Sampling),它的目标是复用旧策略收集的数据,提高样本效率,具体的方法则是通过新旧策略的概率比修正旧数据的权重:
- 其中 θold 是旧策略的参数,θ 是新策略的参数。
(2) 裁剪机制(Clipping)
- 数学目标:限制新旧策略的概率比 rt(θ) 的变化范围,防止更新幅度过大。
- 目标函数
- At 是优势函数(Advantage),衡量当前动作相对于平均水平的优势。
- ϵ 是超参数(如0.2),控制裁剪范围
关于目标函数的推理,我截取了两张CSDN的图关于更新数据的细节,里面详细地写了关于目标函数的由来,也就是关于目标函数的推理过程,里面有一段关于数据更新的详细介绍,如果想了解更多关于PPO的目标函数以及整体训练流程的细节,可以去看原文,地址在图片里面有。PPO算法是一种具体的Actor-Critic算法实现,比如在对话机器人中,输入的prompt是state,输出的response是action,想要得到的策略就是怎么从prompt生成action能够得到最大的reward,也就是拟合人类的偏好。
参考这篇博客的链接,但我也在本文中把PPO目标函数的推导过程,以图片的方式截取的出来,具体可以看看图1 - 图9。
图1 图2 图3 图4 图5 图6 图7
图8 图9
裁剪函数解释:
若 >0(当前动作优于平均),限制 (θ) ≤1+ϵ,避免过度增加该动作的概率。
若 <0(当前动作劣于平均),限制 (θ) ≥1−ϵ,避免过度降低该动作的概率。
下面这张图片直观地感受下裁剪函数的作用,其实就是不要低于下限,不要高于上限。
1.3 PPO的关键优势
- 稳定性:通过裁剪或KL惩罚,避免策略突变导致的性能崩溃。
- 样本高效:支持多轮次(epochs)复用同一批数据,减少环境交互需求。
- 简单易实现:相比TRPO(需要复杂的二阶优化) ,PPO仅需一阶梯度优化。
1.4. PPO的训练流程
- 数据收集:用当前策略与环境交互,生成轨迹数据。
- 计算优势值:使用Critic网络估计每个状态-动作对的优势值 (例如通过GAE方法)。
- 优化目标函数:通过随机梯度上升最大化裁剪目标函数,更新策略参数 θ。
- 迭代更新:重复上述步骤,直到策略收敛。
2. TRPO(Trust Region Policy Optimization)
TRPO(信任区域策略优化) 是一种强化学习算法,旨在通过约束策略更新的幅度来确保训练的稳定性。其核心思想是每次更新策略时,限制新旧策略之间的差异,使其保持在“信任区域”内,从而避免因更新过大导致策略性能骤降。到了这一步就比较清楚了,相对于PPO通过裁剪CLIP进行新旧策略的更新,TRPO则是通过KL散度约束新旧策略的差异,可以让策略在合理范围内更新得更快。核心还是rt(θ)这个比率进行约束,但现在TRPO使用了KL散度这个计算机制,比单纯地进行裁剪会灵活不少。
2.1 TRPO核心目标
- 数学目标:在最大化期望回报的同时,约束新旧策略的差异(通过KL散度)。
2.2 TRPO的训练流程
数据收集:使用当前策略 πθold与环境交互,生成轨迹数据。
计算优势值:估计每个状态-动作对的优势函数 A(s,a) 例如通过广义优势估计 GAE。
构建替代目标函数:利用重要性采样(Importance Sampling)复用旧策略的数据。
约束优化:通过自然梯度法或共轭梯度法,在KL散度的约束下最大化目标函数。
自然梯度法:使用Fisher信息矩阵调整梯度方向,确保更新方向符合参数空间的几何结构。
迭代更新:重复上述过程,逐步优化策略。
3. GRPO (Generalized Reinforcement Learning with Policy Optimization)
GRPO 是一种在线学习算法(online learning algorithm),这意味着它通过使用训练过程中由训练模型自身生成的数据来迭代改进。GRPO 的目标直觉是最大化生成补全(completions)的优势函数(advantage),同时确保模型保持在参考策略(reference policy)附近。
3.1 GRPO进行了哪些改进?
GRPO(Generalized Reinforcement Learning with Policy Optimization)是一种改进的策略优化方法,旨在提高强化学习的稳定性,减少近端策略优化(PPO)中存在的策略崩溃(Policy Collapse)问题,同时保持高效的训练性能。先贴一个GRPO的改进点脑图:
GRPO 主要在 PPO 、 TRPO基础上做了下面的改进:
(1)无需价值函数模型
GRPO去除了PPO中使用的单独的价值函数模型,简化了训练过程,降低了内存使用,提高了效率。也就是说PPO有策略模型、参考模型、奖励模型、价值函数模型等,GRPO则没有价值函数模型(Critic模型),通过群体计算来估计基线。GRPO通过去除价值函数模型,并从群体分数估计基线,而不是要求个体反馈,从而提高强化学习(RL)的效率。大家可以对比下面这张PPO网络的图,里卖弄很明显有个Critic的环节,GRPO其实是去掉了这个环节。
PPO网络 (2)基于组的优势计算
GRPO通过比较一组样本的表现来决定哪些策略应被保留或改进,而不是基于单个样本的绝对奖励。这种方式类似于自然选择过程,只有表现优于平均水平的策略才能生存下来并进一步进化。这种基于群体的方法使得GRPO在处理多样化任务时表现更为稳定,因为它不再依赖于单一样本的表现,而是利用群体智慧来评估策略的优劣。关于这个可以用一个比较通俗的例子说明:
- PPO:就像只有一个固定的食谱,每次做饭时都会按照这个食谱来,但会根据上次的烹饪结果进行微调,使味道逐步优化。
- GRPO:更像是一个团队一起做饭,每个人都有自己独特的食谱和做法。大家通过比较不同的菜品,找到最佳的烹饪方式,而不必详细记录每个人的每一步操作,从而更高效地优化做菜流程,同时减少不必要的记忆和记录工作。
(3)策略约束更松散,提升采样效率
PPO 使用裁剪的目标函数(Clipping)来限制策略更新幅度,但有时会过度限制更新,导致收敛速度变慢;TRPO 通过严格的 KL 散度约束确保策略更新的稳定性,但其优化过程需要二阶优化(如共轭梯度法),计算成本较高,不适用于大规模强化学习任务。GRPO通过裁剪策略和KL散度项的结合,确保模型在探索和稳定性之间取得平衡。这种平衡使得GRPO在复杂任务中表现更为可靠,因为它能够在优化过程中保持策略的稳定性和一致性。
(4)自适应信赖域优化
PPO 裁剪固定范围可能导致策略收敛速度受限,GRPO通过加入 函数动态调整策略更新范围,也就是动态调整KL散度,使策略更新既稳定又高效。这个思想并不稀奇,过往在进行多任务训练、或者进行L1/L2正则化约束的时候也是采用这种机制。
3.2 一个通俗的例子讲一下PPO和GRPO的区别
假设你是一个AI篮球队的教练,正在训练一支5人球队。这些球员是AI智能体(Agents),目标是通过团队协作赢得比赛。
在强化学习框架下,每个球员都有自己的策略(Policy),可以学习如何传球、投篮、抢篮板等动作。但如果每个球员只优化自己的得分,可能会导致:
- 球员抢投:大家都想自己得分,忽略了传球。
- 无视防守:每个人都只想着进攻,而不关注团队整体防守。
- 团队混乱:因为缺乏整体协调,最终的比赛结果不佳。
传统 PPO(Proximal Policy Optimization)的问题,如果我们用**PPO(近端策略优化)**来训练,每个球员都会独立优化自己的回报(Reward):
其中:
- 是球员 i 在状态 选择动作 概率。
- 是个体优势估计(Advantage),衡量某个动作比平均策略好多少。
但问题在于,每个球员只优化自己的表现,不考虑团队整体表现, 其次球员可能出现可能出现自私策略,如盲目抢投、无视队友位置等。
那么GRPO是如何针对这个情况进行改进呢,也就是说如何增加球员之间的配合,提升整体团队的能力。
GRPO 认为:个体的贡献应该相对整个团队来衡量,而不是单独计算。
它的优化方式如下:
1️⃣ 计算团队整体奖励 RgroupR_{\text{group}}Rgroup
除了球员自己的得分外,还要计算整个球队的总表现。例如:
- 比赛胜负:获胜奖励+1,失败惩罚-1。
- 团队配合评分:基于传球、掩护等行为进行奖励。
- 失误次数:如传球失误、被断球等会减少奖励。
2️⃣ 计算组相对优势(Group Relative Advantage)
在 GRPO 中,每个球员的优势要相对团队平均水平进行衡量:
3️⃣ 用 GRPO 的目标函数优化策略
区别:相比传统 PPO,这里的优势函数 不是个体优势,而是相对团队的优势
GRPO 让 AI 球员在学习过程中更关注团队协作,而不仅仅是个体得分,从而提高整体策略优化的稳定性和有效性。
3.3 GRPO 的训练流程
GRPO(Group Relative Policy Optimization,群体相对策略优化)算法,具体是按照以下步骤进行:
(1) 组采样(Group Sampling)
对每个问题 q,从旧策略 πθ 中采样 G 个输出 {o1,o2,…,oG}。例如,若 G=16,则对同一问题生成 16 种不同解法。这一步通过组内样本的多样性,估计当前策略的表现分布。
(2) 优势函数计算(Advantage Calculation)
根据公式计算每个输出的优势值
其中,ri 是第 i 个输出的奖励得分,由奖励模型计算。分子是当前输出奖励与组内平均奖励的差值,衡量相对优势;分母是组内奖励的标准差,用于标准化处理,消除不同问题间的量纲差异。
(3) 目标函数优化(Objective Function Optimization)
根据公式优化策略模型
其中, 是参考策略,通常为初始基座模型。重要性采样比衡量新旧策略对同一动作的概率差异,clip操作限制策略更新的幅度(如 ϵ=0.2),防止过度优化,KL散度惩罚项约束新策略与参考策略的差异,防止过度偏离基座模型的原始能力。其中这个公式可以进一度拆解成下面的计算过程。上面的公式看着很复杂,其实如果从不严谨的角度去分析,你只要关注下面这个计算比率策略 ,就可以了,这个是公式核心中的核心,至于clip和后面的KL散度约束其实还是一些计算上的优化而已。
自适应调整 KL 惩罚系数 :
- 如果 KL 散度过大,说明策略更新太快,需要增大 以限制更新幅度。
- 如果 KL 散度过小,说明策略更新太慢,需要减小 以加快训练进度。
关于KL散度的原理可以参考这篇文章。
(4) 策略模型更新(Policy Model Update)
使用梯度上升法更新策略模型的参数 θ,以最大化目标函数 L(θ)。具体实现时,可以使用优化器(如Adam)进行参数更新。
(5)训练循环(Training Loop)
在每个训练回合中,重复上述步骤,不断更新策略模型,直到达到预定的训练次数或满足收敛条件
4. TRPO 、PPO、GRPO 对比和区别
特性/算法 PPO (近端策略优化) TRPO (信任域策略优化) GRPO (群体相对策略优化) 优势函数计算 使用广义优势估计(GAE)来计算优势函数。 使用蒙特卡洛方法计算优势函数,并通过泰勒级数展开进行近似。 基于组的优势计算,通过比较一组样本的表现来决定哪些策略应被保留或改进。 策略更新方式 通过限制新旧策略的概率比(PPO-Clip)或使用KL散度惩罚(PPO-Penalty)来更新策略。 通过信任域方法限制策略更新的范围,确保新旧策略之间的KL散度不超过预设阈值。 通过群体相对优势估计和直接的KL散度优化来更新策略,无需单独的价值函数模型。 计算复杂度 相对较低,易于实现和调整。 较高,需要计算Hessian矩阵和解决约束优化问题。 通过去除价值函数模型和基于组的优势计算,显著降低了计算复杂度。 适用性 适用于连续动作空间和大规模模型训练。 适用于需要精确控制策略更新幅度的任务,但实现复杂。 适用于需要高效策略优化和减少计算资源的场景,特别是在大规模模型训练中。 稳定性 通过裁剪策略和KL散度项的结合,确保模型在探索和稳定性之间取得平衡。 通过信任域约束确保训练的稳定性,但可能导致训练过程较慢。 通过群体相对优势计算和直接的KL散度优化,提高了训练的稳定性和效率。 训练资源需求 需要额外的价值函数模型和计算资源。 需要大量的计算资源来处理Hessian矩阵和约束优化问题。 通过从群体分数估计基线,显著减少了训练资源的需求。
在本次模型发布中,DeepSeek共发布了三个系列的模型
- R1-Zero:仅通过RL进行训练,未进行SFT的强推理能力模型
- R1:通过融入冷启动数据与多阶段训练提升推理性能的模型
- R1-Distill:在R1基础上,基于Qwen/Llama蒸馏出的系列密集模型
其中一个核心的点就是强化学习的深度使用,在强化学习中,优化策略是一个非常重要的环节,在之前的大模型训练中PPO算法得到了广泛使用,而DeepSeek-R1则进一步使用了GRPO算法,所以本文以DeepSeek-R1为契机,对目前大模型中使用的策略进行总结,
一句话总结下,PPO、TRPO 和 GRPO的关系。PPO、TRPO 和 GRPO 都是用于优化强化学习策略的方法,其中 PPO 通过裁剪控制策略更新,TRPO 通过信赖域和 KL 散度约束保证稳定性,而 GRPO 结合了两者的优点,采用群体相对优势计算和自适应 KL 约束实现更高效的优化,进一步降低了计算复杂度和资源需求。
1. PPO(Proximal Policy Optimization):
1.1 PPO介绍
旨在优化策略网络以最大化累计奖励,同时限制新策略与旧策略之间的差异,确保训练过程的稳定性。它通过引入一个近端策略优化目标函数,使得策略更新能够在保证策略改进的同时,避免更新过大导致模型性能下降。PPO 算法在大模型训练中表现出了良好的性能和稳定性,能够有效地利用样本数据进行学习,适用于各种复杂的任务,如机器人控制、自动驾驶等领域的大模型训练。
其实在ChatGPT最初开源的一个训练流程把PPO policy展示了出来,在第三个环节,如下图:

PPO的核心公式如下所示,

1.2 PPO核心机制
关于PPO网络的核心机制下面是一个介绍,其中非常重要的一个环节是数据重要性采样、裁剪机制、
(1) 重要性采样(Importance Sampling),它的目标是复用旧策略收集的数据,提高样本效率,具体的方法则是通过新旧策略的概率比修正旧数据的权重:

- 其中 θold 是旧策略的参数,θ 是新策略的参数。
(2) 裁剪机制(Clipping)
- 数学目标:限制新旧策略的概率比 rt(θ) 的变化范围,防止更新幅度过大。
- 目标函数

- At 是优势函数(Advantage),衡量当前动作相对于平均水平的优势。
- ϵ 是超参数(如0.2),控制裁剪范围
关于目标函数的推理,我截取了两张CSDN的图关于更新数据的细节,里面详细地写了关于目标函数的由来,也就是关于目标函数的推理过程,里面有一段关于数据更新的详细介绍,如果想了解更多关于PPO的目标函数以及整体训练流程的细节,可以去看原文,地址在图片里面有。PPO算法是一种具体的Actor-Critic算法实现,比如在对话机器人中,输入的prompt是state,输出的response是action,想要得到的策略就是怎么从prompt生成action能够得到最大的reward,也就是拟合人类的偏好。
参考这篇博客的链接,但我也在本文中把PPO目标函数的推导过程,以图片的方式截取的出来,具体可以看看图1 - 图9。










裁剪函数解释:
若 >0(当前动作优于平均),限制 (θ) ≤1+ϵ,避免过度增加该动作的概率。
若 <0(当前动作劣于平均),限制 (θ) ≥1−ϵ,避免过度降低该动作的概率。
下面这张图片直观地感受下裁剪函数的作用,其实就是不要低于下限,不要高于上限。

1.3 PPO的关键优势
- 稳定性:通过裁剪或KL惩罚,避免策略突变导致的性能崩溃。
- 样本高效:支持多轮次(epochs)复用同一批数据,减少环境交互需求。
- 简单易实现:相比TRPO(需要复杂的二阶优化) ,PPO仅需一阶梯度优化。
1.4. PPO的训练流程
- 数据收集:用当前策略与环境交互,生成轨迹数据。
- 计算优势值:使用Critic网络估计每个状态-动作对的优势值 (例如通过GAE方法)。
- 优化目标函数:通过随机梯度上升最大化裁剪目标函数,更新策略参数 θ。
- 迭代更新:重复上述步骤,直到策略收敛。
2. TRPO(Trust Region Policy Optimization)
TRPO(信任区域策略优化) 是一种强化学习算法,旨在通过约束策略更新的幅度来确保训练的稳定性。其核心思想是每次更新策略时,限制新旧策略之间的差异,使其保持在“信任区域”内,从而避免因更新过大导致策略性能骤降。到了这一步就比较清楚了,相对于PPO通过裁剪CLIP进行新旧策略的更新,TRPO则是通过KL散度约束新旧策略的差异,可以让策略在合理范围内更新得更快。核心还是rt(θ)这个比率进行约束,但现在TRPO使用了KL散度这个计算机制,比单纯地进行裁剪会灵活不少。
2.1 TRPO核心目标
- 数学目标:在最大化期望回报的同时,约束新旧策略的差异(通过KL散度)。

2.2 TRPO的训练流程
数据收集:使用当前策略 πθold与环境交互,生成轨迹数据。
计算优势值:估计每个状态-动作对的优势函数 A(s,a) 例如通过广义优势估计 GAE。
构建替代目标函数:利用重要性采样(Importance Sampling)复用旧策略的数据。
约束优化:通过自然梯度法或共轭梯度法,在KL散度的约束下最大化目标函数。
自然梯度法:使用Fisher信息矩阵调整梯度方向,确保更新方向符合参数空间的几何结构。
迭代更新:重复上述过程,逐步优化策略。
3. GRPO (Generalized Reinforcement Learning with Policy Optimization)
GRPO 是一种在线学习算法(online learning algorithm),这意味着它通过使用训练过程中由训练模型自身生成的数据来迭代改进。GRPO 的目标直觉是最大化生成补全(completions)的优势函数(advantage),同时确保模型保持在参考策略(reference policy)附近。
3.1 GRPO进行了哪些改进?
GRPO(Generalized Reinforcement Learning with Policy Optimization)是一种改进的策略优化方法,旨在提高强化学习的稳定性,减少近端策略优化(PPO)中存在的策略崩溃(Policy Collapse)问题,同时保持高效的训练性能。先贴一个GRPO的改进点脑图:

GRPO 主要在 PPO 、 TRPO基础上做了下面的改进:

(1)无需价值函数模型
GRPO去除了PPO中使用的单独的价值函数模型,简化了训练过程,降低了内存使用,提高了效率。也就是说PPO有策略模型、参考模型、奖励模型、价值函数模型等,GRPO则没有价值函数模型(Critic模型),通过群体计算来估计基线。GRPO通过去除价值函数模型,并从群体分数估计基线,而不是要求个体反馈,从而提高强化学习(RL)的效率。大家可以对比下面这张PPO网络的图,里卖弄很明显有个Critic的环节,GRPO其实是去掉了这个环节。

(2)基于组的优势计算
GRPO通过比较一组样本的表现来决定哪些策略应被保留或改进,而不是基于单个样本的绝对奖励。这种方式类似于自然选择过程,只有表现优于平均水平的策略才能生存下来并进一步进化。这种基于群体的方法使得GRPO在处理多样化任务时表现更为稳定,因为它不再依赖于单一样本的表现,而是利用群体智慧来评估策略的优劣。关于这个可以用一个比较通俗的例子说明:
- PPO:就像只有一个固定的食谱,每次做饭时都会按照这个食谱来,但会根据上次的烹饪结果进行微调,使味道逐步优化。
- GRPO:更像是一个团队一起做饭,每个人都有自己独特的食谱和做法。大家通过比较不同的菜品,找到最佳的烹饪方式,而不必详细记录每个人的每一步操作,从而更高效地优化做菜流程,同时减少不必要的记忆和记录工作。
(3)策略约束更松散,提升采样效率
PPO 使用裁剪的目标函数(Clipping)来限制策略更新幅度,但有时会过度限制更新,导致收敛速度变慢;TRPO 通过严格的 KL 散度约束确保策略更新的稳定性,但其优化过程需要二阶优化(如共轭梯度法),计算成本较高,不适用于大规模强化学习任务。GRPO通过裁剪策略和KL散度项的结合,确保模型在探索和稳定性之间取得平衡。这种平衡使得GRPO在复杂任务中表现更为可靠,因为它能够在优化过程中保持策略的稳定性和一致性。
(4)自适应信赖域优化
PPO 裁剪固定范围可能导致策略收敛速度受限,GRPO通过加入 函数动态调整策略更新范围,也就是动态调整KL散度,使策略更新既稳定又高效。这个思想并不稀奇,过往在进行多任务训练、或者进行L1/L2正则化约束的时候也是采用这种机制。
3.2 一个通俗的例子讲一下PPO和GRPO的区别
假设你是一个AI篮球队的教练,正在训练一支5人球队。这些球员是AI智能体(Agents),目标是通过团队协作赢得比赛。
在强化学习框架下,每个球员都有自己的策略(Policy),可以学习如何传球、投篮、抢篮板等动作。但如果每个球员只优化自己的得分,可能会导致:
- 球员抢投:大家都想自己得分,忽略了传球。
- 无视防守:每个人都只想着进攻,而不关注团队整体防守。
- 团队混乱:因为缺乏整体协调,最终的比赛结果不佳。
传统 PPO(Proximal Policy Optimization)的问题,如果我们用**PPO(近端策略优化)**来训练,每个球员都会独立优化自己的回报(Reward):

其中:
- 是球员 i 在状态 选择动作 概率。
- 是个体优势估计(Advantage),衡量某个动作比平均策略好多少。
但问题在于,每个球员只优化自己的表现,不考虑团队整体表现, 其次球员可能出现可能出现自私策略,如盲目抢投、无视队友位置等。
那么GRPO是如何针对这个情况进行改进呢,也就是说如何增加球员之间的配合,提升整体团队的能力。
GRPO 认为:个体的贡献应该相对整个团队来衡量,而不是单独计算。
它的优化方式如下:
1️⃣ 计算团队整体奖励 RgroupR_{\text{group}}Rgroup
除了球员自己的得分外,还要计算整个球队的总表现。例如:

- 比赛胜负:获胜奖励+1,失败惩罚-1。
- 团队配合评分:基于传球、掩护等行为进行奖励。
- 失误次数:如传球失误、被断球等会减少奖励。
2️⃣ 计算组相对优势(Group Relative Advantage)
在 GRPO 中,每个球员的优势要相对团队平均水平进行衡量:


3️⃣ 用 GRPO 的目标函数优化策略

区别:相比传统 PPO,这里的优势函数 不是个体优势,而是相对团队的优势

GRPO 让 AI 球员在学习过程中更关注团队协作,而不仅仅是个体得分,从而提高整体策略优化的稳定性和有效性。
3.3 GRPO 的训练流程
GRPO(Group Relative Policy Optimization,群体相对策略优化)算法,具体是按照以下步骤进行:
(1) 组采样(Group Sampling)
对每个问题 q,从旧策略 πθ 中采样 G 个输出 {o1,o2,…,oG}。例如,若 G=16,则对同一问题生成 16 种不同解法。这一步通过组内样本的多样性,估计当前策略的表现分布。
(2) 优势函数计算(Advantage Calculation)
根据公式计算每个输出的优势值

其中,ri 是第 i 个输出的奖励得分,由奖励模型计算。分子是当前输出奖励与组内平均奖励的差值,衡量相对优势;分母是组内奖励的标准差,用于标准化处理,消除不同问题间的量纲差异。
(3) 目标函数优化(Objective Function Optimization)

根据公式优化策略模型
其中, 是参考策略,通常为初始基座模型。重要性采样比衡量新旧策略对同一动作的概率差异,clip操作限制策略更新的幅度(如 ϵ=0.2),防止过度优化,KL散度惩罚项约束新策略与参考策略的差异,防止过度偏离基座模型的原始能力。其中这个公式可以进一度拆解成下面的计算过程。上面的公式看着很复杂,其实如果从不严谨的角度去分析,你只要关注下面这个计算比率策略 ,就可以了,这个是公式核心中的核心,至于clip和后面的KL散度约束其实还是一些计算上的优化而已。

自适应调整 KL 惩罚系数 :
- 如果 KL 散度过大,说明策略更新太快,需要增大 以限制更新幅度。
- 如果 KL 散度过小,说明策略更新太慢,需要减小 以加快训练进度。
关于KL散度的原理可以参考这篇文章。

(4) 策略模型更新(Policy Model Update)
使用梯度上升法更新策略模型的参数 θ,以最大化目标函数 L(θ)。具体实现时,可以使用优化器(如Adam)进行参数更新。
(5)训练循环(Training Loop)
在每个训练回合中,重复上述步骤,不断更新策略模型,直到达到预定的训练次数或满足收敛条件
4. TRPO 、PPO、GRPO 对比和区别
| 特性/算法 | PPO (近端策略优化) | TRPO (信任域策略优化) | GRPO (群体相对策略优化) |
|---|---|---|---|
| 优势函数计算 | 使用广义优势估计(GAE)来计算优势函数。 | 使用蒙特卡洛方法计算优势函数,并通过泰勒级数展开进行近似。 | 基于组的优势计算,通过比较一组样本的表现来决定哪些策略应被保留或改进。 |
| 策略更新方式 | 通过限制新旧策略的概率比(PPO-Clip)或使用KL散度惩罚(PPO-Penalty)来更新策略。 | 通过信任域方法限制策略更新的范围,确保新旧策略之间的KL散度不超过预设阈值。 | 通过群体相对优势估计和直接的KL散度优化来更新策略,无需单独的价值函数模型。 |
| 计算复杂度 | 相对较低,易于实现和调整。 | 较高,需要计算Hessian矩阵和解决约束优化问题。 | 通过去除价值函数模型和基于组的优势计算,显著降低了计算复杂度。 |
| 适用性 | 适用于连续动作空间和大规模模型训练。 | 适用于需要精确控制策略更新幅度的任务,但实现复杂。 | 适用于需要高效策略优化和减少计算资源的场景,特别是在大规模模型训练中。 |
| 稳定性 | 通过裁剪策略和KL散度项的结合,确保模型在探索和稳定性之间取得平衡。 | 通过信任域约束确保训练的稳定性,但可能导致训练过程较慢。 | 通过群体相对优势计算和直接的KL散度优化,提高了训练的稳定性和效率。 |
| 训练资源需求 | 需要额外的价值函数模型和计算资源。 | 需要大量的计算资源来处理Hessian矩阵和约束优化问题。 | 通过从群体分数估计基线,显著减少了训练资源的需求。 |
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1557


Best Last Month

Brain-Computer Interface Smashes Previous Record for Typing Speed


Theory of Evolutionary Computation – Recent Developments in Discrete Optimization

Google’s PaLM-E is a generalist robot brain that takes commands