News Message
Google Magma Optimizer Algorithm
- by wittx 2026-03-11
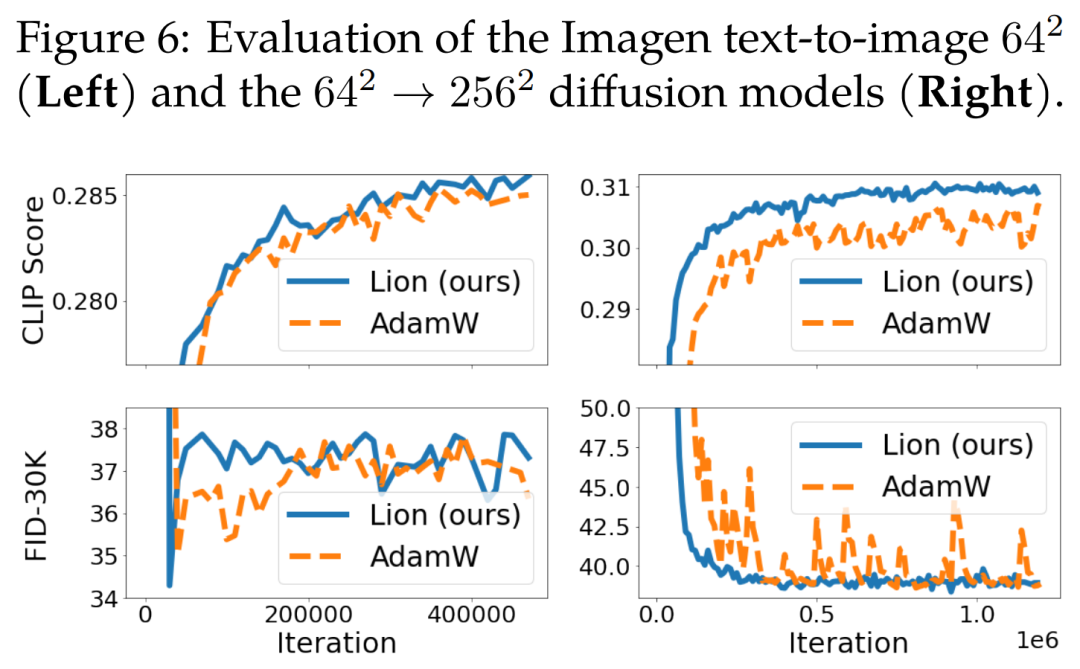
用户发布的文档
加载速度比较慢比较慢,请稍等,手机环境下,有可能无法显示!
" width="100%" height="800">
SkipUpdate:最简单的有效策略
核心算法
- 随机掩码:每个参数块以50%概率被跳过
- 动量保持:即使参数不更新,动量估计仍密集更新
- 无偏校正:缩放因子 s_t = 1/p = 2 保证更新无偏
为什么这能work?理论揭秘
- 惩罚高曲率方向的更新→ 避开"陡峭"的局部最优
- 平滑优化轨迹→ 偏向损失景观的平坦区域
- 隐式实现Sharpness-Aware效果→ 无需SAM的额外计算
Magma:从随机掩码到智能掩码
核心创新:动量-梯度对齐
对齐分数计算
- 高对齐度→ 接近1的缩放因子 → 保留更新
- 低对齐度→ 接近0的缩放因子 → 抑制更新
- 温度参数τ=2 控制敏感度
- ✅零额外开销:仅乘以现有对齐分数,无新增内存/计算
- ✅即插即用:包装任意自适应优化器
- ✅理论保证:保持几何正则化,同时增强稳定性
实验结果:全面碾压SOTA
Llama 2预训练(C4数据集)
MoE架构:复杂优化的试金石
- 与Muon+Magma组合达到最佳性能
- 显著优于Cautious Optimizer(同样利用动量-梯度对齐,但缺乏随机掩码的几何正则化)
重尾噪声环境:Magma的鲁棒性
- 轻尾噪声:Adam和Magma表现相当
- 重尾噪声:Magma大幅领先,且保持更小的条件数(图3 bottom)
异构二次函数:验证理论假设
- 同构结构:两者性能接近
- 异构结构(模拟Transformer特性):Magma收敛更快、最终损失更低
- CNN场景(ResNet-50):Magma无优势,验证了其专属于Transformer-like几何
理论分析:为什么Magma有效?
收敛性保证(Theorem 6)
- 对齐分数同时影响下降效率和噪声水平
- 对高曲率/高方差块的选择性抑制,扩大了稳定学习率范围
- 这解释了为什么Magma对学习率更鲁棒(见附录Figure A3)
与现有工作的区别
方法 | 机制 | 几何正则化 | 额外开销 |
Cautious Optimizer | 确定性掩码(符号冲突时) | ❌ 无 | 无 |
SAM | 对抗扰动 | ✅ 有 | 2x梯度计算 |
GaLore | 子空间投影 | ❌ 无 | 内存节省 |
Magma | 随机掩码+对齐调制 | ✅ 有 | 无 |
消融实验发现
- 仅Attention:22.64 → 21.92 ✅
- Attention + MLP:21.65 ✅✅(最佳)
- 全部层:21.94(略差)
- Element/Row/Column/Block级别效果接近
- 推荐Block级:内存效率最优
学习率鲁棒性
- Adam/C-Adam:在0.001-0.003窗口外性能崩溃
- Magma:在0.0001-0.05范围内保持稳定
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1543


Best Last Month
Information industry
by wittx

Electronic electrician
by wittx
Information industry
by wittx

Information industry
by wittx
Information industry
by wittx

Information industry
by wittx
Information industry
by wittx
Information industry
by wittx

Information industry
by wittx
DeFT: Decoding with Flash Tree-Attention for Efficient Tree-structured LLM Inference