News Message
CVPR 2026放榜!自动驾驶相关论文清单
- by wittx 2026-03-11
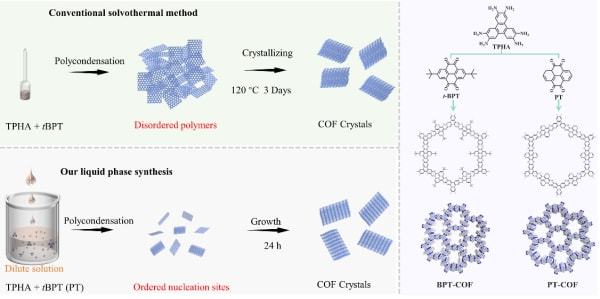
论文标题:学习驾驶是一份免费的礼物:基于非摆拍真实场景视频的大规模无标签自动驾驶预训练
核心亮点:提出LFG无标签教师引导框架,基于无姿态在线第一视角驾驶视频学习自动驾驶表示,结合前馈架构与轻量级自回归模块,利用多模态监督信号联合预测点图、相机姿态等信息,仅用单目相机就在NAVSIM基准测试中超越多相机和激光雷达基线,可作为视频中心的自动驾驶基础模型
原文链接:https://arxiv.org/abs/2602.22091
项目链接:暂未公开
论文标题:LiREC-Net:一种用于激光雷达、RGB和事件校准的无目标、基于学习的网络
核心亮点:提出LiREC-Net无目标学习型多传感器标定网络,在统一框架中联合标定激光雷达、RGB和事件数据等多传感器模态对,引入共享激光雷达表示以减少冗余计算、提升效率,在KITTI和DSEC数据集上表现优于双模态模型,为三模态标定建立新基准。
原文链接:https://arxiv.org/abs/2602.21754
项目链接:暂未公开
论文标题:HorizonForge:使用任意轨迹和任意车辆进行驾驶场景编辑
核心亮点:提出HorizonForge统一框架,将场景重建为可编辑的高斯Splats和网格,支持细粒度3D操控及语言驱动的车辆插入,结合噪声感知视频扩散过程保证时空一致性,同时提出HorizonSuite基准用于标准化评估,相比现有最优方法,用户偏好度提升83.4%,FID指标提升25.19%
原文链接:https://arxiv.org/abs/2602.21333
项目链接:https://horizonforge.github.io/
4. 论文标题:NorD:一种无需推理即可驱动的高效数据视觉-语言-动作模型
核心亮点:提出了NORD(No Reasoning for Driving) 方法,在仅使用不足 60% 数据且完全无需推理标注、Token 量减少 3 倍的条件下仍取得具有竞争力的性能。研究发现标准 GRPO 算法在小数据、无推理标注的训练场景中受难度偏差影响难以有效提升效果,为此引入Dr. GRPO算法缓解该问题,最终在 Waymo 和 NAVSIM 数据集上验证了 NORD 的有效性,在大幅降低数据与标注成本、消除推理开销的同时,实现了更高效的自动驾驶端到端系统。
原文链接:https://arxiv.org/abs/2602.21172
项目链接:https://nord-vla-ai.github.io/
5. VGGDrive:利用跨视图几何接地增强视觉语言模型以实现自动驾驶
核心亮点:提出VGGDrive架构,将成熟3D基础模型的跨视图几何接地能力融入视觉语言模型(VLMs),解决VLMs缺乏跨视图3D几何建模能力的问题;引入即插即用的跨视图3D几何使能器(CVGE),通过分层自适应注入机制衔接3D与2D视觉特征,在5个自动驾驶基准测试中提升基础VLM性能。
原文链接:https://arxiv.org/abs/2602.20794 项目链接:https://github.com/WJ-CV/VGGDrive
核心亮点(此处有误,已在评论区更新)提出VGGDrive架构,将成熟3D基础模型的跨视图几何接地能力融入视觉语言模型(VLMs),解决VLMs缺乏跨视图3D几何建模能力的问题;引入即插即用的跨视图3D几何使能器(CVGE),通过分层自适应注入机制衔接3D与2D视觉特征,在5个自动驾驶基准测试中提升基础VLM性能。 原文链接:https://arxiv.org/abs/2506.09217 项目链接:https://github.com/datadrivenwheels/PCD_Python
核心亮点:提出首个通用、非侵入、3D 一致的对抗物体生成框架,无需修改目标车辆,仅通过在场景中加入渲染物体并采用遮挡感知模块保证跨视角、跨时序的物理合理性,同时基于 BEV 空间特征引导优化对抗物体外观,直接攻击检测器内部特征表示。大量实验表明,所学习的通用对抗物体可从多视角、多距离持续降低多款 BEV 检测器性能,该环境操控式攻击范式揭示了模型对上下文线索的过度依赖,为自动驾驶系统的鲁棒性评估提供了实用可行的 pipeline。 原文链接:https://arxiv.org/abs/2505.22499 项目链接: https://npucvr.github.io/SABER
核心亮点:提出驾驶视觉几何 Transformer(DVGT),可从无位姿的多视角图像序列直接重建全局稠密 3D 点云地图。该方法以 DINO 为骨干提取视觉特征,通过交替的视角内局部注意力、跨视角空间注意力与跨帧时间注意力推理图像间几何关系,再利用多个头解码得到第一帧自车坐标系下的全局点云地图与各帧自车位姿。不同于传统方法依赖精确相机参数,DVGT无需显式 3D 几何先验,能灵活处理任意相机配置,并直接输出带度量尺度的几何结果,省去与外部传感器事后对齐的步骤。nuScenes、OpenScene、Waymo、KITTI、DDAD 等多个大规模驾驶数据集混合训练后,DVGT 在多种场景下性能显著超越现有模型。
原文链接:https://arxiv.org/abs/2512.16919
项目链接:https://github.com/wzzheng/DVGT
核心亮点:提出WAM-Flow,一种将自车轨迹规划建模为结构化 token 空间上离散流匹配的视觉 - 语言 - 动作(VLA)模型。与自回归解码器不同,WAM-Flow 采用全并行、双向去噪方式,支持由粗到细的轨迹优化,并可灵活平衡计算量与精度。该方法整合了通过三元组边际学习保留标量几何信息的度量对齐数值 tokenizer、几何感知流目标函数,以及模拟器引导的 GRPO 对齐策略,在保持并行生成的同时融合安全、进度与舒适性奖励。通过多阶段适配,将预训练自回归骨干网络 Janus-1.5B 转换为非因果流模型,并通过持续多模态预训练提升道路场景理解能力。得益于一致性模型训练与并行解码推理的特性,WAM-Flow 在闭环性能上优于自回归与扩散类 VLA 基线,在 NAVSIM v1 基准上,1 步推理达到 89.1 PDMS,5 步推理达到 90.3 PDMS,证明离散流匹配是端到端自动驾驶中极具潜力的新范式。
原文链接:https://arxiv.org/abs/2512.06112
项目链接:https://github.com/fudan-generative-vision/WAM-Flow?tab=readme-ov-file
核心亮点(此处有误,已在评论区更新)提出WAM-Flow,一种将自车轨迹规划建模为结构化 token 空间上离散流匹配的视觉 - 语言 - 动作(VLA)模型。与自回归解码器不同,WAM-Flow 采用全并行、双向去噪方式,支持由粗到细的轨迹优化,并可灵活平衡计算量与精度。该方法整合了通过三元组边际学习保留标量几何信息的度量对齐数值 tokenizer、几何感知流目标函数,以及模拟器引导的 GRPO 对齐策略,在保持并行生成的同时融合安全、进度与舒适性奖励。通过多阶段适配,将预训练自回归骨干网络 Janus-1.5B 转换为非因果流模型,并通过持续多模态预训练提升道路场景理解能力。得益于一致性模型训练与并行解码推理的特性,WAM-Flow 在闭环性能上优于自回归与扩散类 VLA 基线,在 NAVSIM v1 基准上,1 步推理达到 89.1 PDMS,5 步推理达到 90.3 PDMS,证明离散流匹配是端到端自动驾驶中极具潜力的新范式。
原文链接:https://arxiv.org/abs/2512.20563
项目链接:https://github.com/autonomousvision/lead?tab=readme-ov-file
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1542


Best Last Month