News Message
AI设计AI:Google DeepMind 揭示的博弈论算法进化之路
- by wittx 2026-03-11
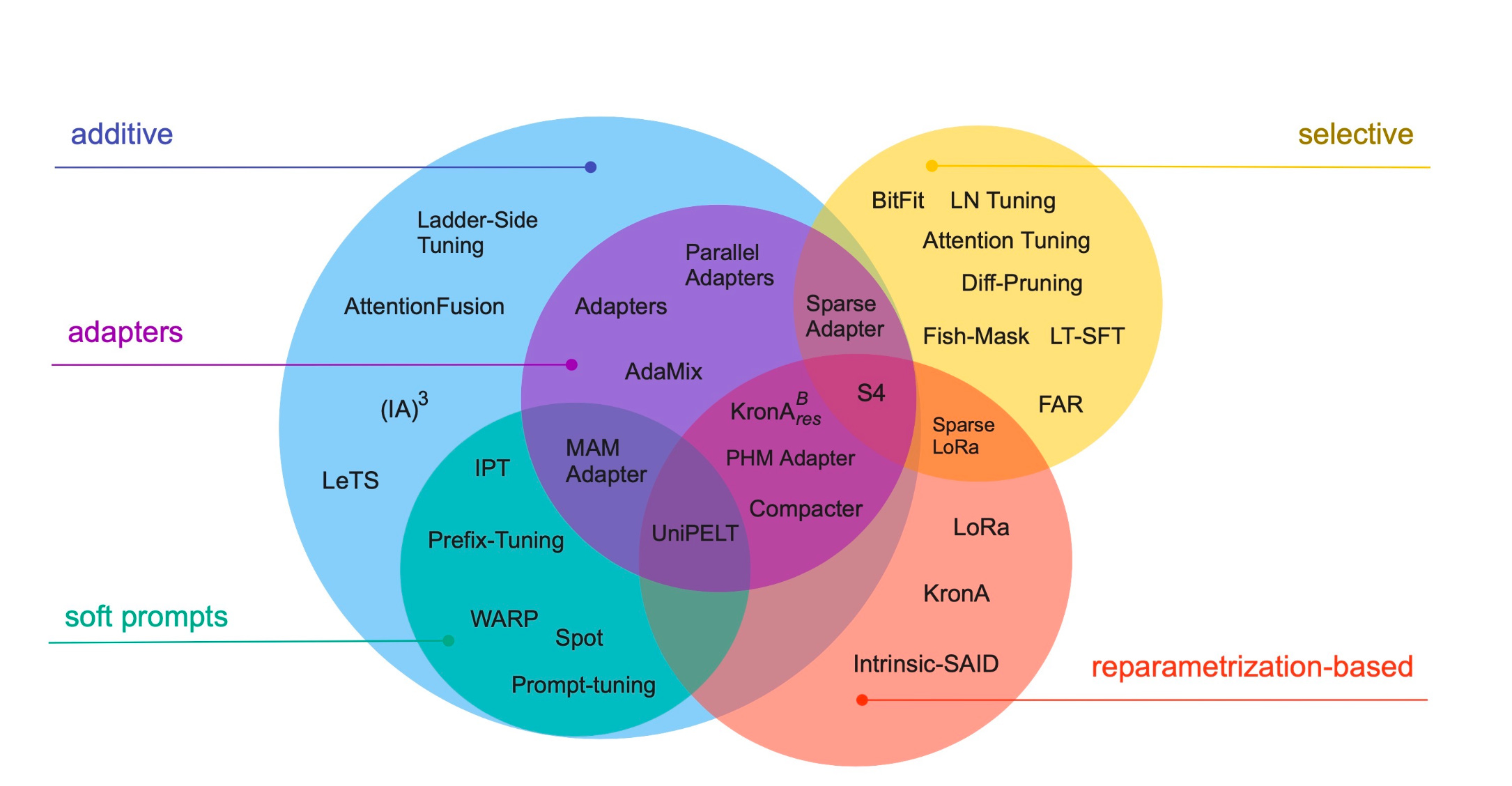
用户发布的文档
加载速度比较慢比较慢,请稍等,手机环境下,有可能无法显示!
" width="100%" height="800">
Google DeepMind的AlphaEvolve,它是一种突破性的人工智能算法演化进化框架,专门用于自动发现、设计和优化算法,并能在数学、计算机科学和工程等复杂领域中发现并提出新的高效算法。AlphaEvolve 可在没有人干预的情况下,通过多轮“生成 → 评估 → 选择 → 改进”的迭代,形成更有效、更具创新性的算法,而非一次性生成。 这篇成果《Discovering Multi-agent Learning Algorithms with Large Language Models》是基于AlphaEvolve在多智能体强化学习上取得的突破,AI4Science不仅仅是概念,它正在取得实质性的成果和进展。
https://arxiv.org/pdf/2602.16928 1. 引言:打破人类直觉的瓶颈
在多智能体强化学习(MARL)的竞技场上,从德州扑克到《星际争霸 II》,AI 早已展现出超凡的博弈能力。然而,这些辉煌战绩背后的核心算法——无论是反事实悔恨最小化(CFR)的变体,还是策略空间响应奥德赛(PSRO)——本质上依然是“人类作品”。长期以来,算法逻辑的微调高度依赖顶尖专家的直觉与无数次的工程试错。 这种“人类直觉”正在成为算法进一步突破的瓶颈。我们习惯于设计对称、简洁且数学上易于处理的公式,但这真的是通往纳什均衡的最短路径吗?Google DeepMind 发布的AlphaEvolve给出了否定答案。这是一个利用大语言模型(LLM,如 Gemini)自动“进化”出新算法的框架,它不再只是辅助编程,而是直接接管了算法架构师的角色,揭示了那些人类难以直觉感知、却异常高效的博弈逻辑。 2. AlphaEvolve:LLM 不仅仅会聊天,它还是“代码进化大师”
AlphaEvolve 的核心机制在于将算法发现视为一场“符号进化”(Symbolic Evolution)。它不同于传统的超参数微调,而是直接将算法源代码视为“基因组”,利用 LLM 强大的语义理解能力作为“智能遗传算子”。 LLM 能够理解代码背后的逻辑意图,从而进行有意义的变异:它会重写核心控制流、注入复杂的符号操作,甚至在代码中嵌入动态调节机制。这种方法让算法的优化从“数值层面”跃升到了“逻辑层面”。我们正在进入一个算法不再需要人类解释,而只需要人类设定目标的“自动驾驶”时代。
3. VAD-CFR 的“健忘”智慧:波动率自适应折现
在进化出的首个重磅算法VAD-CFR(波动率自适应折现 CFR)中,AI 展现了超越人类设计的灵活性。传统的折现算法(如 DCFR)使用固定的历史数据权重,但 VAD-CFR 引入了“波动率感知的记忆调节”: 混沌中加速遗忘:算法通过指数加权移动平均(EWMA)追踪悔恨值的波动。当感知到策略剧烈波动(高波动率)时,算法会动态大幅折现,快速“忘记”那些不稳定的历史。
非直觉的 1.1x 瞬时加速:进化过程捕捉到了一个极为细微的细节——非对称瞬时增强(Asymmetric Instantaneous Boosting)。VAD-CFR 会将正向瞬时悔恨值乘以 1.1 倍的系数,而负向则保持不变。这种人类极少尝试的“不对称性”,让算法能更敏锐地捕捉并剥削有利的偏离。
这种机制证明了:在博弈的混沌中,适时的“健忘”和对机会的不对称放大,比死记硬背更接近最优解。 4. 非直觉的“硬冷启动”:让子弹先飞 500 轮
VAD-CFR 最令研究者感到震撼的发现,是其在 1000 次迭代实验中所采取的硬冷启动(Hard Warm-start)策略。 策略累积的绝对延迟:在实验的前 500 轮中,VAD-CFR 竟然选择完全停止策略累积,仅仅进行悔恨值的更新。对于人类设计师而言,这种“浪费”一半计算资源的行为几乎是不可思议的。
基于悔恨强度的信息过滤:在 500 轮之后,VAD-CFR 并非线性累积,而是引入了悔恨强度权重(Regret-Magnitude Weighting)。它会根据瞬时悔恨值的绝对大小对策略进行加权,从而构建最终的平衡。
通过‘硬冷启动’有效地过滤了早期探索阶段产生的巨大噪音,并利用强度权重确保最终的平衡策略仅从高信息量的迭代中提炼,彻底避免了早期策略剧变对最终解质量的污染。 5. SHOR-PSRO 的混血基因:稳定性与贪婪的动态平衡
针对大型博弈,AlphaEvolve 进化出了SHOR-PSRO算法。其核心是一个巧妙的“混合元求解器”(Hybrid Meta-solver),它在“稳健性”与“贪婪性”之间找到了完美的平衡点。 该算法将稳健的“乐观悔恨匹配(ORM)”与激进的“平滑最佳纯策略(Softmax 分布)”进行了线性融合。更为精妙的是其全自动的动态退火机制(Annealing Schedule): 多样性奖励:从初期的 0.05 衰减至后期的 0.001,确保早期充分探索。 融合因子调节:混合权重从 0.3 平滑降至 0.05。 温度控制:Softmax 分布的温度从 0.5 降至 0.01。
这种从“广度搜索”到“深度收敛”的自动化转型,完美解决了标准 PSRO 在面对庞大策略空间时的效率瓶颈。 6. 算法不对称性:训练与评估的“双重人格”
SHOR-PSRO 揭示了一个人类设计者常因追求“简洁美感”而忽略的深层逻辑:训练与评估的不对称性。AI 为这两个阶段进化出了截然不同的配置: 训练端(追求稳定性):配置 1000+ 次内部迭代,并返回平均策略(Average Strategy)。这种做法能平滑训练中的随机噪音,确护航策略(Oracle)的稳步提升。 评估端(追求灵敏度):配置高达 8000+ 次的内部迭代,将混合因子锁定在 0.01 的极低水平,并直接返回最后一次迭代(Last-iterate)的策略。
这种“重反应”的评估设定能更精准、更敏感地捕捉剥削度(Exploitability)。人类追求数学上的对称与统一,而 AI 追求极致的性能,即便这意味着代码实现会变得不再“优雅”。 7. 结语:当人类灵感遇见 AI 洞察
AlphaEvolve 的成功预示着算法研发模式的范式转移。未来的顶级算法将不再诞生于白板前的灵光一现,而是由人类设定宏观框架,由 AI 进行微观逻辑的符号进化。当 AI 能够进化出比人类几十年心血更优的博弈逻辑时,人类在科学发现中的角色是否会从亲力亲为的“架构师”,转向负责设定目标与判别优劣的“评委”?
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1539


Best Last Month
Information industry
by wittx
Information industry
by wittx

Information industry
by wittx
Information industry
by wittx

Information industry
by wittx
Information industry
by wittx

Information industry
by wittx

Information industry
by wittx

Information industry
by wittx
Information industry
by wittx