News Message
ICLR2025 金融论文汇总
- by wittx 2026-03-04
1. 《Bilevel Reinforcement Learning for Stock Data with A Conservative TD Ensemble》
论文链接:https://openreview.net/pdf?id=zaDU4vMAUr
作者:Haochen Yuan, Minting Pan, Yunbo Wang, Xiaokang Yang
摘要:强化学习(RL)在股票交易中显示出巨大潜力。典型的方法是通过历史离线数据优化累积回报,但这可能导致策略过于“记忆”离线数据中的最优买卖行为,而忽略了金融市场非平稳的特性。本文将股票交易视为一种特定的离线RL问题,并提出了MetaTrader方法,包含两个关键贡献:一是引入了一种新颖的双层演员-评论家方法,涵盖原始股票数据及其变换;二是提出了保守TD学习的新变体,利用基于集成的TD目标来减轻有限离线数据中的价值高估问题。在两个公开数据集上的实证结果表明,MetaTrader优于现有的方法,包括基于RL的方法和股票预测模型。
2. 《Advancing Algorithmic Trading with Large Language Models: A Reinforcement Learning Approach for Stock Market Optimization》
论文连接:https://openreview.net/pdf?id=w7BGq6ozOL
作者:Ali Riahi Samani, Fateme Golivand Darvishvand, Feng Chen
摘要:在金融市场快速发展的背景下,有效的决策工具对于应对经济指标和市场动态带来的复杂性至关重要。算法交易策略因其能够自主执行交易而受到关注,其中深度强化学习(DRL)是一种通过持续市场互动优化交易行为的关键方法。然而,基于RL的系统在适应时间序列数据的演变和整合非结构化文本信息方面面临挑战。最近,大模型(LLM)的发展为解决这些问题提供了新机遇。LLM能够分析大量数据,为传统市场分析提供补充。本文提出了一种将六种不同的LLM整合到算法交易框架中的新方法,开发了Stock-Evol-Instruct算法,使RL代理能够利用LLM驱动的见解优化每日股票交易决策。通过使用Silver和JPMorgan的真实股票数据进行实证评估,证明了这种方法在超越传统交易模型方面的巨大潜力。
3. 《QuantBench: Benchmarking AI Methods for Quantitative Investment》
论文链接:https://arxiv.org/pdf/2504.18600
作者:Saizhuo Wang, Fengrui Hua, Yiyan Qi, Wanyun Zhou, Hao Kong, Lionel Ni, Jian Guo
摘要:人工智能(AI)在量化投资领域的应用取得了显著进展,但缺乏与行业实践一致的标准基准,阻碍了研究进展和学术创新的实践应用。本文介绍了QuantBench,这是一个工业级的基准平台,旨在解决这一关键需求。QuantBench具有三个关键优势:(1)与量化投资行业实践一致的标准;(2)整合各种AI算法的灵活性;(3)涵盖整个量化投资过程的全流程覆盖。使用QuantBench的实证研究表明了一些关键的研究方向,包括解决分布偏移问题所需的持续学习、改进关系金融数据建模方法以及在低信噪比环境中减轻过拟合的更稳健方法。通过为评估提供共同基础并促进研究人员与从业者之间的合作,QuantBench旨在加速AI在量化投资中的进步,类似于计算机视觉和自然语言处理领域中基准平台的影响。
4. 《Benchmarking Machine Learning Methods for Stock Prediction》
论文链接:https://openreview.net/pdf?id=bsXxNkhvm6
作者:Hongkai Jiang, Wu Zhu, Xiaolin Hu
摘要:机器学习在股票运动预测中得到了广泛应用,但该领域的研究常常受到缺乏高质量基准数据集和综合评估方法的限制。为解决这些挑战,本文介绍了BenchStock,这是一个包含来自美国和中国两大股票市场的标准化数据集以及用于全面评估机器学习股票预测方法的评估方法的基准。该基准涵盖了从传统机器学习技术到最新的深度学习方法的各种模型。使用BenchStock,作者在两个市场中进行了大规模实验,预测了三个十年的个股回报,以评估短期和长期表现。为了评估这些预测在实际市场条件下的影响,作者根据预测构建了一个投资组合,并使用回测程序模拟其表现。实验揭示了几个未被报告的关键发现:1)大多数方法在美国市场的表现超过了标普500指数,但在中国市场遭受了重大损失。2)一种方法的预测准确性与其投资组合回报之间没有相关性。3)先进的深度学习方法并没有超越传统方法。4)模型的表现高度依赖于测试周期。这些发现突出了股票预测的复杂性,并呼吁在该领域进行更深入的机器学习研究。
5. 《Leveraging Diffusion Transformers for Stock Factor Augmentation in Financial Markets》
论文链接:https://openreview.net/pdf?id=bRMfqThoVC
作者:Yuan Gao, Haokun Chen, Xiang Wang, Zhicai Wang, Xue Wang, Jinyang Gao, Bolin Ding
摘要:数据稀缺性是训练股票预测机器学习模型的重大挑战,常常导致信噪比低和数据同质化,从而降低模型性能。为解决这些问题,本文介绍了DiffsFormer,这是一种利用基于Transformer的扩散模型生成人工智能样本(AIGS)的新方法。DiffsFormer最初在大规模源域上进行训练,通过条件引导捕捉全局联合分布,并通过编辑特定下游任务的现有样本进行训练增强,允许控制生成数据与目标域的偏差。作者在CSI300和CSI800数据集上使用八种常用的机器学习模型对DiffsFormer进行了评估,分别实现了7.3%和22.1%的年化回报率相对提升。广泛的实验为DiffsFormer的功能及其组成部分提供了见解,说明了它们在缓解数据稀缺性和增强模型性能方面的作用。作者的发现证明了AIGS和DiffsFormer在解决股票预测中的数据限制方面的潜力,能够生成逼真的股票因子并控制编辑过程。
6. 《Distributional Reinforcement Learning Based On Historical Information For Option Hedging》
论文链接:https://openreview.net/pdf?id=rcCNk4AI2J
作者:Qiao Pan, Long Zhu, Zhaoju Wang
摘要:期权是广泛用于风险管理的企业运营和金融衍生工具。期权对冲旨在通过买卖其他金融产品来缓解资产价格波动带来的投资风险。基于Black-Scholes模型的传统对冲策略由于假设波动率恒定且忽略交易成本而存在实际限制。最近,强化学习(RL)在期权对冲策略研究中受到关注,但仍存在几个挑战:当前方法依赖于实时市场数据(例如标的资产价格、持仓量、剩余期权期限)来确定最优头寸,未能充分利用历史数据的潜在价值;现有方法侧重于预期对冲成本,忽略了成本的全面分布;在训练数据生成方面,常用的单一模拟方法在特定条件下表现良好,但在确保模型在多样化数据集上的鲁棒性方面存在困难。为解决这些问题,作者提出了一种基于历史信息的新型分布强化学习期权对冲方法。历史状态被纳入状态变量中,通过门控循环单元(GRU)网络层提取历史信息。然后将其与来自全连接层的当前信息结合起来,以告知后续网络层,确保代理在学习对冲策略时同时考虑当前和历史市场信息。价值网络的输出被设置为一系列分位数,通过Quantile Huber Loss函数拟合它们的分布,以基于分布而非期望值评估策略。为多样化数据源,作者使用Black-Scholes模型、二叉树模型和Heston模型的组合来模拟大量期权数据。实验结果表明,该方法显著降低了对冲成本,并在各种市场条件下表现出强大的适应性和实用性。
7. 《MIGA: Mixture-of-Experts with Group Aggregation for Stock Market Prediction》
论文链接:https://arxiv.org/pdf/2410.02241
作者:Zhaojian Yu, Yinghao Wu, Chaozheng Wang
摘要:股票市场预测多年来一直是一个极具挑战性的问题,因为其固有的高波动性和低信息噪声比。基于机器学习或深度学习的现有解决方案通过在整个股票数据集上训练单一模型来生成所有类型股票的预测,表现出优越的性能。然而,由于股票风格和市场趋势的显著变化,单一端到端模型难以充分捕捉这些风格化股票特征的差异,导致对所有类型股票的预测相对不准确。本文提出了MIGA,一种新颖的混合专家与组聚合框架,旨在通过动态切换不同的风格专家为不同风格的股票生成专业预测。为了促进MIGA中不同专家之间的协作,作者提出了一种新颖的内组注意力架构,使同一组内的专家能够共享信息,从而提高所有专家的整体性能。因此,MIGA在包括CSI300、CSI500和CSI1000在内的三个中国股指基准测试中显著优于其他端到端模型。值得注意的是,MIGA-Conv在CSI300基准测试中实现了24%的超额年回报率,超过了之前最先进的模型8%的绝对值。
8. 《A Benchmark Study For Limit Order Book (LOB) Models and Time Series Forecasting Models on LOB Data》
论文链接:https://openreview.net/pdf?id=MhD9rLeU31
作者:Weijian Li, Stephen S Cheng, Lining Mao, Jigyasa Kumari, Alex Pyo, Mehak Kawatra, Jialong Li, Jiayi Wang, Ammar Gilani, Jingya Xun, Jerry Yao-Chieh Hu, Han Liu
摘要:作者提出了一个全面的基准,用于评估深度学习模型在限价订单簿(LOB)数据上的表现。该工作做出了四项重大贡献:(i)在专有的期货LOB数据集上评估现有的LOB模型,以检验LOB模型在不同资产之间的性能转移性;(ii)首次对LOB模型在中点价格回报预测(MPRF)任务上的表现进行了基准测试。(iii)首次对现有的时间序列预测模型在MPRF任务上的表现进行了基准研究,以弥合通用时间序列预测领域和LOB时间序列预测领域之间的差距;(iv)提出了一种卷积交叉变量混合层(CVML)的架构,作为任何深度学习多变量时间序列模型的附加组件,以显著提高LOB数据上的MPRF性能。该实证结果突出了在专有期货LOB数据集上的基准研究的价值,展示了常用开源股票LOB数据集与期货数据集之间的性能差距。此外,结果表明,LOB感知的模型设计对于在LOB数据集上实现最佳预测性能至关重要。最重要的是,该结果表明作者提出的CVML架构平均提高了各种时间序列模型中点价格回报预测性能的244.9%。
9. 《DiT-LSTM-SVAR Model For Portfolios》
论文链接:https://openreview.net/pdf?id=MeOi6u9E23
作者:Yuxing Yuan, Ziwei Wang, Zhenyuan Huang, Haijun Yang
摘要:本文提出了一个名为DiT-LSTM-SVAR的新颖组合模型,首次将金融市场微观结构与深度学习网络相结合,以提高投资组合的性能。作者使用DiT模型预测股票的上涨和下跌走势,并基于SVAR模型的信息分解模型识别随机游走股票。DiT模块显著提高了马修斯相关系数,提高了近3%。投资组合的年回报率提高了近20%。SVAR模块显著提高了马修斯相关系数,提高了近4%。基于市场和公共信息的DiT-LSTM-SVAR模块构建的投资组合优于基于DiT-LSTM模型构建的投资组合。该投资组合的年累积回报率为266.60%,夏普比率为1.8。
10. 《AlphaQCM: Alpha Discovery with Distributional Reinforcement Learning》
论文链接:https://openreview.net/pdf?id=IS7kW28VVt
作者:Zhoufan Zhu, Ke Zhu
摘要:在金融领域,研究人员和从业者发现协同公式化阿尔法非常重要但极具挑战性。本文从序列决策的角度重新考虑了公式化阿尔法的发现过程,并将整个阿尔法挖掘过程概念化为一个非平稳且奖励稀疏的马尔可夫决策过程。为了克服非平稳性和奖励稀疏性的挑战,作者提出了AlphaQCM方法,这是一种新颖的分布强化学习方法,旨在高效地搜索协同公式化阿尔法。AlphaQCM方法首先通过Q网络和分位数网络分别学习Q函数和分位数。然后,AlphaQCM方法应用分位数条件矩方法从可能有偏的分位数中学习无偏方差。在所学的Q函数和方差的指导下,AlphaQCM方法在探索公式化阿尔法的巨大搜索空间时,能够有效地应对非平稳性和奖励稀疏性。对真实世界数据集的实证应用表明,AlphaQCM方法显著优于其竞争对手,特别是在处理包含众多股票的大型数据集时。
11. 《ContraSim: Contrastive Similarity Space Learning for Financial Market Predictions》
论文链接:https://arxiv.org/pdf/2502.16023v1
作者:Nicholas Vinden, Raeid Saqur, Zining Zhu, Frank Rudzicz
摘要:作者介绍了对比相似性空间嵌入算法(ContraSim),这是一个用于揭示每日金融新闻标题与市场走势之间全局语义关系的新框架。ContraSim包含两个关键阶段:(i)加权新闻标题增强,它生成增强的金融新闻标题以及语义细粒度相似性分数;(ii)加权自监督对比学习(WSSCL),这是经典自监督对比学习的扩展版本,它使用相似性度量来创建改进的加权嵌入空间。这个嵌入空间将语义相似的新闻标题聚集在一起,便于更深入地洞察市场。实证结果表明,将ContraSim特征整合到金融预测任务中可以将从《华尔街日报》新闻标题进行分类的准确率提高7%。此外,通过信息密度分析,作者发现ContraSim构建的相似性空间内在地将具有同质市场走势方向的日期聚集在一起,表明ContraSim能够独立于真实标签捕捉市场动态。此外,ContraSim能够识别出与当前新闻标题密切相似的历史新闻日,为分析师提供可操作的见解,通过参考类似的历史事件来预测市场趋势。
12. 《Operator Deep Smoothing for Implied Volatility》
论文链接:https://arxiv.org/pdf/2406.11520
作者:Ruben Wiedemann, Antoine Jacquier, Lukas Gonon
摘要:作者开发了一种基于神经算子的隐含波动率现报新方法。在金融行业,隐含波动率现报通常被称为隐含波动率平滑,即构建一个与给定期权市场上当前观察到的价格一致的平滑曲面。期权价格数据以高度动态的方式在不断变化的空间配置中出现,这给使用经典神经网络的基础机器学习方法带来了重大限制。尽管在语言和图像处理领域的大模型在处理大量原始数据上取得了突破性成果,但在金融工程中,从大型历史数据集中进行泛化一直受到需要大量数据预处理的限制。特别是,隐含波动率平滑一直是一个逐个实例、手工操作的过程,无论是基于神经网络的方法还是传统的参数化策略。作者的通用“算子深度平滑”方法直接将观察到的数据映射到平滑曲面。作者调整了图神经算子架构,以高精度处理十年的原始日内标普500期权数据,使用单个模型实例。训练后的算子遵守关键的无套利约束,并且对于输入的子采样(在实践中出现在异常值去除的上下文中)具有鲁棒性。作者提供了广泛的历史基准,并在与经典神经网络和SVI(行业标准的隐含波动率参数化)的比较中展示了该方法的泛化能力。因此,算子深度平滑方法为在金融工程中使用神经网络处理大型历史数据集开辟了道路。
13. 《InvestESG: A multi-agent reinforcement learning benchmark for studying climate investment as a social dilemma》
论文链接:https://arxiv.org/pdf/2411.09856
作者:Xiaoxuan Hou, Jiayi Yuan, Joel Z Leibo, Natasha Jaques
摘要:InvestESG是一个新颖的多智能体强化学习(MARL)基准,旨在研究环境、社会和治理(ESG)披露要求对公司气候投资的影响。该基准模拟了一个跨时间的社会困境,公司需要在气候缓解努力带来的短期利润损失和降低气候风险带来的长期利益之间进行权衡,而ESG意识强的投资者则试图通过投资决策影响公司行为。公司在减缓、漂绿和适应性投资之间分配资本,不同的策略会影响气候结果和投资者偏好。作者正在发布InvestESG的开源版本,分别基于PyTorch和JAX,这些版本能够进行可扩展且硬件加速的模拟,以研究缓解气候变化的替代激励机制。该实验表明,在没有足够资本的ESG意识强的投资者的情况下,公司的减缓努力在披露要求下仍然有限。然而,当有足够多的投资者优先考虑ESG时,公司的合作行为会增加,这反过来又会减少气候风险并增强长期金融稳定性。此外,提供更多关于全球气候风险的信息会鼓励公司增加减缓投资,即使没有投资者参与。该发现与使用真实世界数据的实证研究一致,突显了MARL在通过高效测试替代政策和市场设计为政策制定提供信息方面的潜力,以应对大规模社会经济挑战。
14. 《OracleMamba: A Dynamic Market-Guided and Time State Selection Framework for Robust Stock Prediction》
论文链接:https://openreview.net/pdf?id=0x8wWloW2O
作者:Song-Li Wu
摘要:股票价格预测是一个复杂的问题,因为金融市场的固有波动性和宏观经济条件、资本流动和市场情绪等多种因素的影响。最近的联合股票预测模型专注于从单个股票价格序列中提取时间模式,并将它们结合起来模拟股票相关性。然而,这些模型面临两个关键限制:首先,在长期预测中,它们保留了信息丰富和过多的状态,放大了噪声并增加了复杂性;其次,在短期预测中,它们优先考虑市场指数和技术指标,忽略了市场情绪的实时影响,而市场情绪可以独立于传统指标推动价格变动。虽然状态空间模型(SSMs)如Mamba提高了效率并捕捉了长距离关系,但它们仍然在性能上落后于Transformer基模型。 为了解决这些挑战,作者提出了OracleMamba,这是一个新颖的框架,它整合了一个动态市场引导模块用于短期预测和一个SelectiveMamba模块用于长期预测。动态市场引导模块融合了客观市场数据和主观情绪分析,以增强短期预测的准确性。SelectiveMamba模块通过3D扫描机制高效地捕捉光谱和时间特征,该机制从时间序列数据中提取和筛选关键信号。通过整合光谱特征来识别市场节奏和时间特征来跟踪价格随时间的变动,SelectiveMamba模块减少了噪声并保留了关键信息以用于长期预测。该框架显著提高了模型的效率和准确性,在现实世界的股票预测任务中优于现有方法。
1. 《Bilevel Reinforcement Learning for Stock Data with A Conservative TD Ensemble》
论文链接:https://openreview.net/pdf?id=zaDU4vMAUr
作者:Haochen Yuan, Minting Pan, Yunbo Wang, Xiaokang Yang
摘要:强化学习(RL)在股票交易中显示出巨大潜力。典型的方法是通过历史离线数据优化累积回报,但这可能导致策略过于“记忆”离线数据中的最优买卖行为,而忽略了金融市场非平稳的特性。本文将股票交易视为一种特定的离线RL问题,并提出了MetaTrader方法,包含两个关键贡献:一是引入了一种新颖的双层演员-评论家方法,涵盖原始股票数据及其变换;二是提出了保守TD学习的新变体,利用基于集成的TD目标来减轻有限离线数据中的价值高估问题。在两个公开数据集上的实证结果表明,MetaTrader优于现有的方法,包括基于RL的方法和股票预测模型。

2. 《Advancing Algorithmic Trading with Large Language Models: A Reinforcement Learning Approach for Stock Market Optimization》
论文连接:https://openreview.net/pdf?id=w7BGq6ozOL
作者:Ali Riahi Samani, Fateme Golivand Darvishvand, Feng Chen
摘要:在金融市场快速发展的背景下,有效的决策工具对于应对经济指标和市场动态带来的复杂性至关重要。算法交易策略因其能够自主执行交易而受到关注,其中深度强化学习(DRL)是一种通过持续市场互动优化交易行为的关键方法。然而,基于RL的系统在适应时间序列数据的演变和整合非结构化文本信息方面面临挑战。最近,大模型(LLM)的发展为解决这些问题提供了新机遇。LLM能够分析大量数据,为传统市场分析提供补充。本文提出了一种将六种不同的LLM整合到算法交易框架中的新方法,开发了Stock-Evol-Instruct算法,使RL代理能够利用LLM驱动的见解优化每日股票交易决策。通过使用Silver和JPMorgan的真实股票数据进行实证评估,证明了这种方法在超越传统交易模型方面的巨大潜力。

3. 《QuantBench: Benchmarking AI Methods for Quantitative Investment》
论文链接:https://arxiv.org/pdf/2504.18600
作者:Saizhuo Wang, Fengrui Hua, Yiyan Qi, Wanyun Zhou, Hao Kong, Lionel Ni, Jian Guo
摘要:人工智能(AI)在量化投资领域的应用取得了显著进展,但缺乏与行业实践一致的标准基准,阻碍了研究进展和学术创新的实践应用。本文介绍了QuantBench,这是一个工业级的基准平台,旨在解决这一关键需求。QuantBench具有三个关键优势:(1)与量化投资行业实践一致的标准;(2)整合各种AI算法的灵活性;(3)涵盖整个量化投资过程的全流程覆盖。使用QuantBench的实证研究表明了一些关键的研究方向,包括解决分布偏移问题所需的持续学习、改进关系金融数据建模方法以及在低信噪比环境中减轻过拟合的更稳健方法。通过为评估提供共同基础并促进研究人员与从业者之间的合作,QuantBench旨在加速AI在量化投资中的进步,类似于计算机视觉和自然语言处理领域中基准平台的影响。

4. 《Benchmarking Machine Learning Methods for Stock Prediction》
论文链接:https://openreview.net/pdf?id=bsXxNkhvm6
作者:Hongkai Jiang, Wu Zhu, Xiaolin Hu
摘要:机器学习在股票运动预测中得到了广泛应用,但该领域的研究常常受到缺乏高质量基准数据集和综合评估方法的限制。为解决这些挑战,本文介绍了BenchStock,这是一个包含来自美国和中国两大股票市场的标准化数据集以及用于全面评估机器学习股票预测方法的评估方法的基准。该基准涵盖了从传统机器学习技术到最新的深度学习方法的各种模型。使用BenchStock,作者在两个市场中进行了大规模实验,预测了三个十年的个股回报,以评估短期和长期表现。为了评估这些预测在实际市场条件下的影响,作者根据预测构建了一个投资组合,并使用回测程序模拟其表现。实验揭示了几个未被报告的关键发现:1)大多数方法在美国市场的表现超过了标普500指数,但在中国市场遭受了重大损失。2)一种方法的预测准确性与其投资组合回报之间没有相关性。3)先进的深度学习方法并没有超越传统方法。4)模型的表现高度依赖于测试周期。这些发现突出了股票预测的复杂性,并呼吁在该领域进行更深入的机器学习研究。
5. 《Leveraging Diffusion Transformers for Stock Factor Augmentation in Financial Markets》
论文链接:https://openreview.net/pdf?id=bRMfqThoVC
作者:Yuan Gao, Haokun Chen, Xiang Wang, Zhicai Wang, Xue Wang, Jinyang Gao, Bolin Ding
摘要:数据稀缺性是训练股票预测机器学习模型的重大挑战,常常导致信噪比低和数据同质化,从而降低模型性能。为解决这些问题,本文介绍了DiffsFormer,这是一种利用基于Transformer的扩散模型生成人工智能样本(AIGS)的新方法。DiffsFormer最初在大规模源域上进行训练,通过条件引导捕捉全局联合分布,并通过编辑特定下游任务的现有样本进行训练增强,允许控制生成数据与目标域的偏差。作者在CSI300和CSI800数据集上使用八种常用的机器学习模型对DiffsFormer进行了评估,分别实现了7.3%和22.1%的年化回报率相对提升。广泛的实验为DiffsFormer的功能及其组成部分提供了见解,说明了它们在缓解数据稀缺性和增强模型性能方面的作用。作者的发现证明了AIGS和DiffsFormer在解决股票预测中的数据限制方面的潜力,能够生成逼真的股票因子并控制编辑过程。

6. 《Distributional Reinforcement Learning Based On Historical Information For Option Hedging》
论文链接:https://openreview.net/pdf?id=rcCNk4AI2J
作者:Qiao Pan, Long Zhu, Zhaoju Wang
摘要:期权是广泛用于风险管理的企业运营和金融衍生工具。期权对冲旨在通过买卖其他金融产品来缓解资产价格波动带来的投资风险。基于Black-Scholes模型的传统对冲策略由于假设波动率恒定且忽略交易成本而存在实际限制。最近,强化学习(RL)在期权对冲策略研究中受到关注,但仍存在几个挑战:当前方法依赖于实时市场数据(例如标的资产价格、持仓量、剩余期权期限)来确定最优头寸,未能充分利用历史数据的潜在价值;现有方法侧重于预期对冲成本,忽略了成本的全面分布;在训练数据生成方面,常用的单一模拟方法在特定条件下表现良好,但在确保模型在多样化数据集上的鲁棒性方面存在困难。为解决这些问题,作者提出了一种基于历史信息的新型分布强化学习期权对冲方法。历史状态被纳入状态变量中,通过门控循环单元(GRU)网络层提取历史信息。然后将其与来自全连接层的当前信息结合起来,以告知后续网络层,确保代理在学习对冲策略时同时考虑当前和历史市场信息。价值网络的输出被设置为一系列分位数,通过Quantile Huber Loss函数拟合它们的分布,以基于分布而非期望值评估策略。为多样化数据源,作者使用Black-Scholes模型、二叉树模型和Heston模型的组合来模拟大量期权数据。实验结果表明,该方法显著降低了对冲成本,并在各种市场条件下表现出强大的适应性和实用性。

7. 《MIGA: Mixture-of-Experts with Group Aggregation for Stock Market Prediction》
论文链接:https://arxiv.org/pdf/2410.02241
作者:Zhaojian Yu, Yinghao Wu, Chaozheng Wang
摘要:股票市场预测多年来一直是一个极具挑战性的问题,因为其固有的高波动性和低信息噪声比。基于机器学习或深度学习的现有解决方案通过在整个股票数据集上训练单一模型来生成所有类型股票的预测,表现出优越的性能。然而,由于股票风格和市场趋势的显著变化,单一端到端模型难以充分捕捉这些风格化股票特征的差异,导致对所有类型股票的预测相对不准确。本文提出了MIGA,一种新颖的混合专家与组聚合框架,旨在通过动态切换不同的风格专家为不同风格的股票生成专业预测。为了促进MIGA中不同专家之间的协作,作者提出了一种新颖的内组注意力架构,使同一组内的专家能够共享信息,从而提高所有专家的整体性能。因此,MIGA在包括CSI300、CSI500和CSI1000在内的三个中国股指基准测试中显著优于其他端到端模型。值得注意的是,MIGA-Conv在CSI300基准测试中实现了24%的超额年回报率,超过了之前最先进的模型8%的绝对值。

8. 《A Benchmark Study For Limit Order Book (LOB) Models and Time Series Forecasting Models on LOB Data》
论文链接:https://openreview.net/pdf?id=MhD9rLeU31
作者:Weijian Li, Stephen S Cheng, Lining Mao, Jigyasa Kumari, Alex Pyo, Mehak Kawatra, Jialong Li, Jiayi Wang, Ammar Gilani, Jingya Xun, Jerry Yao-Chieh Hu, Han Liu
摘要:作者提出了一个全面的基准,用于评估深度学习模型在限价订单簿(LOB)数据上的表现。该工作做出了四项重大贡献:(i)在专有的期货LOB数据集上评估现有的LOB模型,以检验LOB模型在不同资产之间的性能转移性;(ii)首次对LOB模型在中点价格回报预测(MPRF)任务上的表现进行了基准测试。(iii)首次对现有的时间序列预测模型在MPRF任务上的表现进行了基准研究,以弥合通用时间序列预测领域和LOB时间序列预测领域之间的差距;(iv)提出了一种卷积交叉变量混合层(CVML)的架构,作为任何深度学习多变量时间序列模型的附加组件,以显著提高LOB数据上的MPRF性能。该实证结果突出了在专有期货LOB数据集上的基准研究的价值,展示了常用开源股票LOB数据集与期货数据集之间的性能差距。此外,结果表明,LOB感知的模型设计对于在LOB数据集上实现最佳预测性能至关重要。最重要的是,该结果表明作者提出的CVML架构平均提高了各种时间序列模型中点价格回报预测性能的244.9%。

9. 《DiT-LSTM-SVAR Model For Portfolios》
论文链接:https://openreview.net/pdf?id=MeOi6u9E23
作者:Yuxing Yuan, Ziwei Wang, Zhenyuan Huang, Haijun Yang
摘要:本文提出了一个名为DiT-LSTM-SVAR的新颖组合模型,首次将金融市场微观结构与深度学习网络相结合,以提高投资组合的性能。作者使用DiT模型预测股票的上涨和下跌走势,并基于SVAR模型的信息分解模型识别随机游走股票。DiT模块显著提高了马修斯相关系数,提高了近3%。投资组合的年回报率提高了近20%。SVAR模块显著提高了马修斯相关系数,提高了近4%。基于市场和公共信息的DiT-LSTM-SVAR模块构建的投资组合优于基于DiT-LSTM模型构建的投资组合。该投资组合的年累积回报率为266.60%,夏普比率为1.8。

10. 《AlphaQCM: Alpha Discovery with Distributional Reinforcement Learning》
论文链接:https://openreview.net/pdf?id=IS7kW28VVt
作者:Zhoufan Zhu, Ke Zhu
摘要:在金融领域,研究人员和从业者发现协同公式化阿尔法非常重要但极具挑战性。本文从序列决策的角度重新考虑了公式化阿尔法的发现过程,并将整个阿尔法挖掘过程概念化为一个非平稳且奖励稀疏的马尔可夫决策过程。为了克服非平稳性和奖励稀疏性的挑战,作者提出了AlphaQCM方法,这是一种新颖的分布强化学习方法,旨在高效地搜索协同公式化阿尔法。AlphaQCM方法首先通过Q网络和分位数网络分别学习Q函数和分位数。然后,AlphaQCM方法应用分位数条件矩方法从可能有偏的分位数中学习无偏方差。在所学的Q函数和方差的指导下,AlphaQCM方法在探索公式化阿尔法的巨大搜索空间时,能够有效地应对非平稳性和奖励稀疏性。对真实世界数据集的实证应用表明,AlphaQCM方法显著优于其竞争对手,特别是在处理包含众多股票的大型数据集时。

11. 《ContraSim: Contrastive Similarity Space Learning for Financial Market Predictions》
论文链接:https://arxiv.org/pdf/2502.16023v1
作者:Nicholas Vinden, Raeid Saqur, Zining Zhu, Frank Rudzicz
摘要:作者介绍了对比相似性空间嵌入算法(ContraSim),这是一个用于揭示每日金融新闻标题与市场走势之间全局语义关系的新框架。ContraSim包含两个关键阶段:(i)加权新闻标题增强,它生成增强的金融新闻标题以及语义细粒度相似性分数;(ii)加权自监督对比学习(WSSCL),这是经典自监督对比学习的扩展版本,它使用相似性度量来创建改进的加权嵌入空间。这个嵌入空间将语义相似的新闻标题聚集在一起,便于更深入地洞察市场。实证结果表明,将ContraSim特征整合到金融预测任务中可以将从《华尔街日报》新闻标题进行分类的准确率提高7%。此外,通过信息密度分析,作者发现ContraSim构建的相似性空间内在地将具有同质市场走势方向的日期聚集在一起,表明ContraSim能够独立于真实标签捕捉市场动态。此外,ContraSim能够识别出与当前新闻标题密切相似的历史新闻日,为分析师提供可操作的见解,通过参考类似的历史事件来预测市场趋势。

12. 《Operator Deep Smoothing for Implied Volatility》
论文链接:https://arxiv.org/pdf/2406.11520
作者:Ruben Wiedemann, Antoine Jacquier, Lukas Gonon
摘要:作者开发了一种基于神经算子的隐含波动率现报新方法。在金融行业,隐含波动率现报通常被称为隐含波动率平滑,即构建一个与给定期权市场上当前观察到的价格一致的平滑曲面。期权价格数据以高度动态的方式在不断变化的空间配置中出现,这给使用经典神经网络的基础机器学习方法带来了重大限制。尽管在语言和图像处理领域的大模型在处理大量原始数据上取得了突破性成果,但在金融工程中,从大型历史数据集中进行泛化一直受到需要大量数据预处理的限制。特别是,隐含波动率平滑一直是一个逐个实例、手工操作的过程,无论是基于神经网络的方法还是传统的参数化策略。作者的通用“算子深度平滑”方法直接将观察到的数据映射到平滑曲面。作者调整了图神经算子架构,以高精度处理十年的原始日内标普500期权数据,使用单个模型实例。训练后的算子遵守关键的无套利约束,并且对于输入的子采样(在实践中出现在异常值去除的上下文中)具有鲁棒性。作者提供了广泛的历史基准,并在与经典神经网络和SVI(行业标准的隐含波动率参数化)的比较中展示了该方法的泛化能力。因此,算子深度平滑方法为在金融工程中使用神经网络处理大型历史数据集开辟了道路。
13. 《InvestESG: A multi-agent reinforcement learning benchmark for studying climate investment as a social dilemma》
论文链接:https://arxiv.org/pdf/2411.09856
作者:Xiaoxuan Hou, Jiayi Yuan, Joel Z Leibo, Natasha Jaques
摘要:InvestESG是一个新颖的多智能体强化学习(MARL)基准,旨在研究环境、社会和治理(ESG)披露要求对公司气候投资的影响。该基准模拟了一个跨时间的社会困境,公司需要在气候缓解努力带来的短期利润损失和降低气候风险带来的长期利益之间进行权衡,而ESG意识强的投资者则试图通过投资决策影响公司行为。公司在减缓、漂绿和适应性投资之间分配资本,不同的策略会影响气候结果和投资者偏好。作者正在发布InvestESG的开源版本,分别基于PyTorch和JAX,这些版本能够进行可扩展且硬件加速的模拟,以研究缓解气候变化的替代激励机制。该实验表明,在没有足够资本的ESG意识强的投资者的情况下,公司的减缓努力在披露要求下仍然有限。然而,当有足够多的投资者优先考虑ESG时,公司的合作行为会增加,这反过来又会减少气候风险并增强长期金融稳定性。此外,提供更多关于全球气候风险的信息会鼓励公司增加减缓投资,即使没有投资者参与。该发现与使用真实世界数据的实证研究一致,突显了MARL在通过高效测试替代政策和市场设计为政策制定提供信息方面的潜力,以应对大规模社会经济挑战。
14. 《OracleMamba: A Dynamic Market-Guided and Time State Selection Framework for Robust Stock Prediction》
论文链接:https://openreview.net/pdf?id=0x8wWloW2O
作者:Song-Li Wu
摘要:股票价格预测是一个复杂的问题,因为金融市场的固有波动性和宏观经济条件、资本流动和市场情绪等多种因素的影响。最近的联合股票预测模型专注于从单个股票价格序列中提取时间模式,并将它们结合起来模拟股票相关性。然而,这些模型面临两个关键限制:首先,在长期预测中,它们保留了信息丰富和过多的状态,放大了噪声并增加了复杂性;其次,在短期预测中,它们优先考虑市场指数和技术指标,忽略了市场情绪的实时影响,而市场情绪可以独立于传统指标推动价格变动。虽然状态空间模型(SSMs)如Mamba提高了效率并捕捉了长距离关系,但它们仍然在性能上落后于Transformer基模型。 为了解决这些挑战,作者提出了OracleMamba,这是一个新颖的框架,它整合了一个动态市场引导模块用于短期预测和一个SelectiveMamba模块用于长期预测。动态市场引导模块融合了客观市场数据和主观情绪分析,以增强短期预测的准确性。SelectiveMamba模块通过3D扫描机制高效地捕捉光谱和时间特征,该机制从时间序列数据中提取和筛选关键信号。通过整合光谱特征来识别市场节奏和时间特征来跟踪价格随时间的变动,SelectiveMamba模块减少了噪声并保留了关键信息以用于长期预测。该框架显著提高了模型的效率和准确性,在现实世界的股票预测任务中优于现有方法。

Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1532


Best Last Month


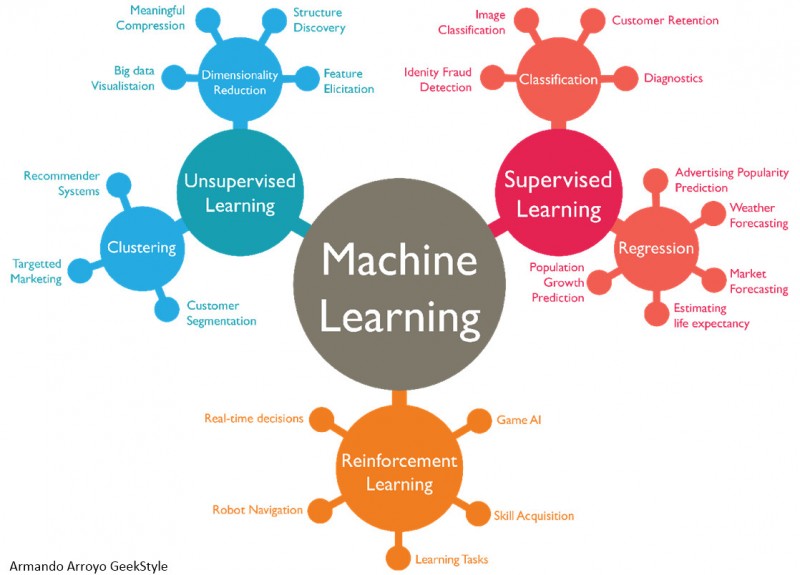
Actor-Attention-Critic for Multi-Agent Reinforcement Learning