News Message
谷歌发表了2篇强化学习新论文
- by wittx 2026-03-04
用户发布的文档
Google近期发了2篇论文分别从机制设计和自动化发现两个角度,推动了多智能体强化学习(MARL)领域的发展。

概览
论文 核心主题 发表时间 Multi-agent cooperation through in-context co-player inference 通过上下文共玩家推理实现多智能体协作 2026年2月19日 Discovering Multiagent Learning Algorithms with Large Language Models 使用大语言模型自动发现多智能体学习算法 2026年2月24日
Multi-agent协作

Multi-agent cooperation through in-context co-player inference 在多智能体强化学习中,实现自利益智能体之间的稳健协作是一个根本性挑战。传统方法面临两大难题:
均衡选择问题:在一般和博弈中,存在多个纳什均衡,独立优化的智能体往往收敛到次优结果(如社会困境中的相互背叛) 环境非平稳性:从单个智能体视角,其他智能体同时学习导致环境动态变化
现有的"共玩家学习感知"(co-player learning awareness)方法通常依赖硬编码的假设或严格区分"朴素学习者"与"元学习者"的时间尺度分离。
1.2 核心创新:上下文共玩家推理
本文的核心假设是:训练序列模型智能体对抗多样化的共玩家分布,可以自然诱导出上下文最佳响应策略,无需显式的元梯度或时间尺度分离。

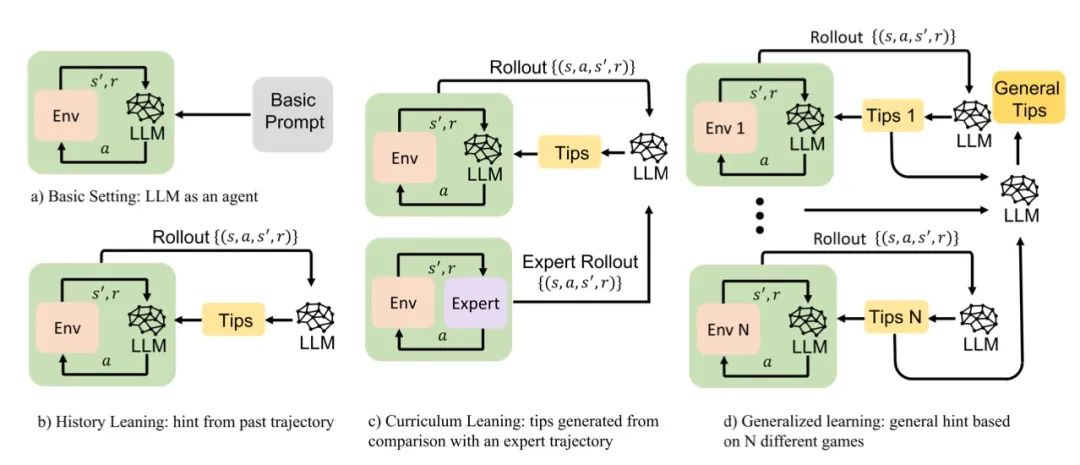
图1:混合训练诱导稳健协作。在混合池(学习智能体+表格型智能体)中训练的RL智能体收敛到合作(实线)。消融实验显示:仅对抗其他学习智能体(虚线)或提供显式共玩家标识(点线)都会导致背叛。
1.3 协作机制的三步因果链
论文通过系统性实验验证了一个从多样性到协作的完整因果链条:
Step 1: 多样性诱导上下文最佳响应机制
训练智能体仅对抗随机表格型智能体池,发现智能体能够在单局游戏中快速识别对手并收敛到最佳响应。

图2A-B:上下文最佳响应的涌现。PPI智能体(仅对抗表格型对手训练)在评估时针对不同固定策略表现出快速适应能力。
Step 2: 上下文学习者易受剥削
冻结Step 1的智能体作为"固定上下文学习者"(Fixed-ICL),训练新智能体专门剥削它。新智能体学会了通过塑造Fixed-ICL的学习动态来获取更高收益——这就是剥削(extortion)策略。

图2C-D:学习剥削上下文学习者。新训练的RL智能体通过利用Fixed-ICL的适应倾向,迫使其进入不公平的合作。
Step 3: 相互剥削驱动协作
两个从Step 2初始化的剥削智能体相互对抗时,它们相互塑造对方的上下文学习动态,最终收敛到合作行为。

图2E-F:从相互剥削到协作。两个剥削策略的相互塑造在单局内(F)和跨局训练(E)中都推动了合作行为的学习。
1.4 关键结论
发现 意义 上下文学习作为"快速时间尺度"的朴素学习 无需显式区分元/内循环 混合训练池是关键 缺乏多样性会导致机制退化 剥削脆弱性作为协作的驱动力 揭示了社会困境中合作涌现的新机制
理论贡献:论文提出了Predictive Policy Improvement (PPI)算法,并证明了在完美世界模型假设下,预测均衡对应于主观嵌入均衡(Subjective Embedded Equilibrium)。
AlphaEvolve: 自动发现多智能体学习算法

Discovering Multiagent Learning Algorithms with Large Language Models 多智能体强化学习的算法设计长期依赖人工迭代优化。虽然CFR和PSRO等基础方法有坚实的理论基础,但其最有效的变体往往依赖人类直觉来导航庞大的算法设计空间。
本文提出使用AlphaEvolve——一个由大语言模型驱动的进化编码智能体——来自动发现新的多智能体学习算法。
2.2 方法框架:AlphaEvolve
AlphaEvolve将LLM的代码生成能力与进化算法的严格选择压力相结合:
循环:
1. 基于适应度选择父代算法
2. 使用LLM(Gemini 2.5 Pro)提出语义上有意义的代码修改
3. 在代理游戏上自动评估候选算法
4. 将有效候选加入种群
2.3 发现一:VAD-CFR(波动率自适应折扣CFR)
在CFR领域,AlphaEvolve发现了Volatility-Adaptive Discounted (VAD-)CFR,其包含三个非直观机制:
机制 描述 传统方法对比 波动率自适应折扣 基于瞬时遗憾幅度的EWMA动态调整折扣参数 DCFR使用固定折扣因子 非对称瞬时增强 正瞬时遗憾增强1.1倍 传统方法对称处理 硬热启动+遗憾幅度加权 延迟至第500轮开始策略平均,并按遗憾幅度加权 标准CFR从t=1开始线性平均

图1:CFR变体在训练和测试游戏上的性能。VAD-CFR(紫色线)在大多数游戏中展现出最快的收敛速度和最低的可利用度。
关键代码结构(简化):
class RegretAccumulator:
"""Volatility-Adaptive Discounting & Asymmetric Boosting"""
def update_accumulate_regret(self, info_state_node, iteration_number, cfr_regrets):
# 1. 计算波动率和自适应折扣
inst_mag = max(abs(r) for r in cfr_regrets.values())
self.ewma = 0.1 * inst_mag + 0.9 * self.ewma
volatility = min(1.0, self.ewma / 2.0)
# 2. 非对称增强
r_boosted = r * 1.1if r > 0else r
# 3. 符号相关的历史折扣
discount = disc_pos if prev_R >= 0else disc_neg
2.4 发现二:SHOR-PSRO(平滑混合乐观遗憾PSRO)
在PSRO领域,AlphaEvolve发现了Smoothed Hybrid Optimistic Regret (SHOR-)PSRO,其核心创新是:
混合元求解器架构:
乐观遗憾匹配(ORM):提供稳定性 平滑最佳纯策略(Softmax):通过温度控制的softmax积极偏向高收益模式 动态退火调度:混合因子λ从0.3→0.05退火,多样性奖励从0.05→0.001衰减

图2:PSRO变体性能对比。SHOR-PSRO(棕色线)在复杂游戏(如6面Liar's Dice)上显著优于静态基线。
训练与评估的非对称设计:
组件 训练时 评估时 混合因子 λ 0.3 → 0.05(退火) 固定 0.01 多样性奖励 0.05 → 0.001(衰减) 0.0 返回策略 平均策略 最后迭代策略 内部迭代次数 1000 + 20×(种群大小-1) 8000 + 50×(种群大小-1)
2.5 完整游戏测试结果

图3:CFR变体在全部11个游戏上的性能。VAD-CFR在10/11个游戏中达到或超越SOTA。

图4:PSRO变体在全部11个游戏上的性能。SHOR-PSRO在8/11个游戏中达到或超越SOTA。
两篇论文总结
维度 论文一(机制) 论文二(自动化) 核心问题 协作如何自然涌现 如何自动发现有效算法 关键洞察 上下文学习替代显式元学习 LLM可以进化出非直观的符号算法 方法范式 decentralized MARL + 多样性训练 进化算法 + LLM代码生成 验证环境 Iterated Prisoner's Dilemma Kuhn Poker, Leduc Poker, Goofspiel, Liar's Dice 实践意义 为Foundation Model多智能体系统提供可扩展路径 将算法设计从手工调参转向自动化发现
https://arxiv.org/pdf/2602.16928
Discovering Multiagent Learning Algorithms with Large Language Models
https://arxiv.org/pdf/2602.16301
Multi-agent cooperation through in-context co-player inference
推荐阅读
Google近期发了2篇论文分别从机制设计和自动化发现两个角度,推动了多智能体强化学习(MARL)领域的发展。
概览
| Multi-agent cooperation through in-context co-player inference | ||
| Discovering Multiagent Learning Algorithms with Large Language Models |
Multi-agent协作
在多智能体强化学习中,实现自利益智能体之间的稳健协作是一个根本性挑战。传统方法面临两大难题:
均衡选择问题:在一般和博弈中,存在多个纳什均衡,独立优化的智能体往往收敛到次优结果(如社会困境中的相互背叛) 环境非平稳性:从单个智能体视角,其他智能体同时学习导致环境动态变化
现有的"共玩家学习感知"(co-player learning awareness)方法通常依赖硬编码的假设或严格区分"朴素学习者"与"元学习者"的时间尺度分离。
1.2 核心创新:上下文共玩家推理
本文的核心假设是:训练序列模型智能体对抗多样化的共玩家分布,可以自然诱导出上下文最佳响应策略,无需显式的元梯度或时间尺度分离。
图1:混合训练诱导稳健协作。在混合池(学习智能体+表格型智能体)中训练的RL智能体收敛到合作(实线)。消融实验显示:仅对抗其他学习智能体(虚线)或提供显式共玩家标识(点线)都会导致背叛。
1.3 协作机制的三步因果链
论文通过系统性实验验证了一个从多样性到协作的完整因果链条:
Step 1: 多样性诱导上下文最佳响应机制
训练智能体仅对抗随机表格型智能体池,发现智能体能够在单局游戏中快速识别对手并收敛到最佳响应。
图2A-B:上下文最佳响应的涌现。PPI智能体(仅对抗表格型对手训练)在评估时针对不同固定策略表现出快速适应能力。
Step 2: 上下文学习者易受剥削
冻结Step 1的智能体作为"固定上下文学习者"(Fixed-ICL),训练新智能体专门剥削它。新智能体学会了通过塑造Fixed-ICL的学习动态来获取更高收益——这就是剥削(extortion)策略。
图2C-D:学习剥削上下文学习者。新训练的RL智能体通过利用Fixed-ICL的适应倾向,迫使其进入不公平的合作。
Step 3: 相互剥削驱动协作
两个从Step 2初始化的剥削智能体相互对抗时,它们相互塑造对方的上下文学习动态,最终收敛到合作行为。
图2E-F:从相互剥削到协作。两个剥削策略的相互塑造在单局内(F)和跨局训练(E)中都推动了合作行为的学习。
1.4 关键结论
理论贡献:论文提出了Predictive Policy Improvement (PPI)算法,并证明了在完美世界模型假设下,预测均衡对应于主观嵌入均衡(Subjective Embedded Equilibrium)。
AlphaEvolve: 自动发现多智能体学习算法
多智能体强化学习的算法设计长期依赖人工迭代优化。虽然CFR和PSRO等基础方法有坚实的理论基础,但其最有效的变体往往依赖人类直觉来导航庞大的算法设计空间。
本文提出使用AlphaEvolve——一个由大语言模型驱动的进化编码智能体——来自动发现新的多智能体学习算法。
2.2 方法框架:AlphaEvolve
AlphaEvolve将LLM的代码生成能力与进化算法的严格选择压力相结合:
循环:
1. 基于适应度选择父代算法
2. 使用LLM(Gemini 2.5 Pro)提出语义上有意义的代码修改
3. 在代理游戏上自动评估候选算法
4. 将有效候选加入种群
2.3 发现一:VAD-CFR(波动率自适应折扣CFR)
在CFR领域,AlphaEvolve发现了Volatility-Adaptive Discounted (VAD-)CFR,其包含三个非直观机制:
| 波动率自适应折扣 | ||
| 非对称瞬时增强 | ||
| 硬热启动+遗憾幅度加权 |
图1:CFR变体在训练和测试游戏上的性能。VAD-CFR(紫色线)在大多数游戏中展现出最快的收敛速度和最低的可利用度。
关键代码结构(简化):
class RegretAccumulator:
"""Volatility-Adaptive Discounting & Asymmetric Boosting"""
def update_accumulate_regret(self, info_state_node, iteration_number, cfr_regrets):
# 1. 计算波动率和自适应折扣
inst_mag = max(abs(r) for r in cfr_regrets.values())
self.ewma = 0.1 * inst_mag + 0.9 * self.ewma
volatility = min(1.0, self.ewma / 2.0)
# 2. 非对称增强
r_boosted = r * 1.1if r > 0else r
# 3. 符号相关的历史折扣
discount = disc_pos if prev_R >= 0else disc_neg
2.4 发现二:SHOR-PSRO(平滑混合乐观遗憾PSRO)
在PSRO领域,AlphaEvolve发现了Smoothed Hybrid Optimistic Regret (SHOR-)PSRO,其核心创新是:
混合元求解器架构:
乐观遗憾匹配(ORM):提供稳定性 平滑最佳纯策略(Softmax):通过温度控制的softmax积极偏向高收益模式 动态退火调度:混合因子λ从0.3→0.05退火,多样性奖励从0.05→0.001衰减
图2:PSRO变体性能对比。SHOR-PSRO(棕色线)在复杂游戏(如6面Liar's Dice)上显著优于静态基线。
训练与评估的非对称设计:
2.5 完整游戏测试结果
图3:CFR变体在全部11个游戏上的性能。VAD-CFR在10/11个游戏中达到或超越SOTA。
图4:PSRO变体在全部11个游戏上的性能。SHOR-PSRO在8/11个游戏中达到或超越SOTA。
两篇论文总结
| 核心问题 | ||
| 关键洞察 | ||
| 方法范式 | ||
| 验证环境 | ||
| 实践意义 |
https://arxiv.org/pdf/2602.16928
Discovering Multiagent Learning Algorithms with Large Language Models
https://arxiv.org/pdf/2602.16301
Multi-agent cooperation through in-context co-player inference
推荐阅读
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1529


Best Last Month
.jpg)

CoCa: Contrastive Captioners are Image-Text Foundation Models