News Message
Deep learning guided design of protease substrates
- by wittx 2026-03-04
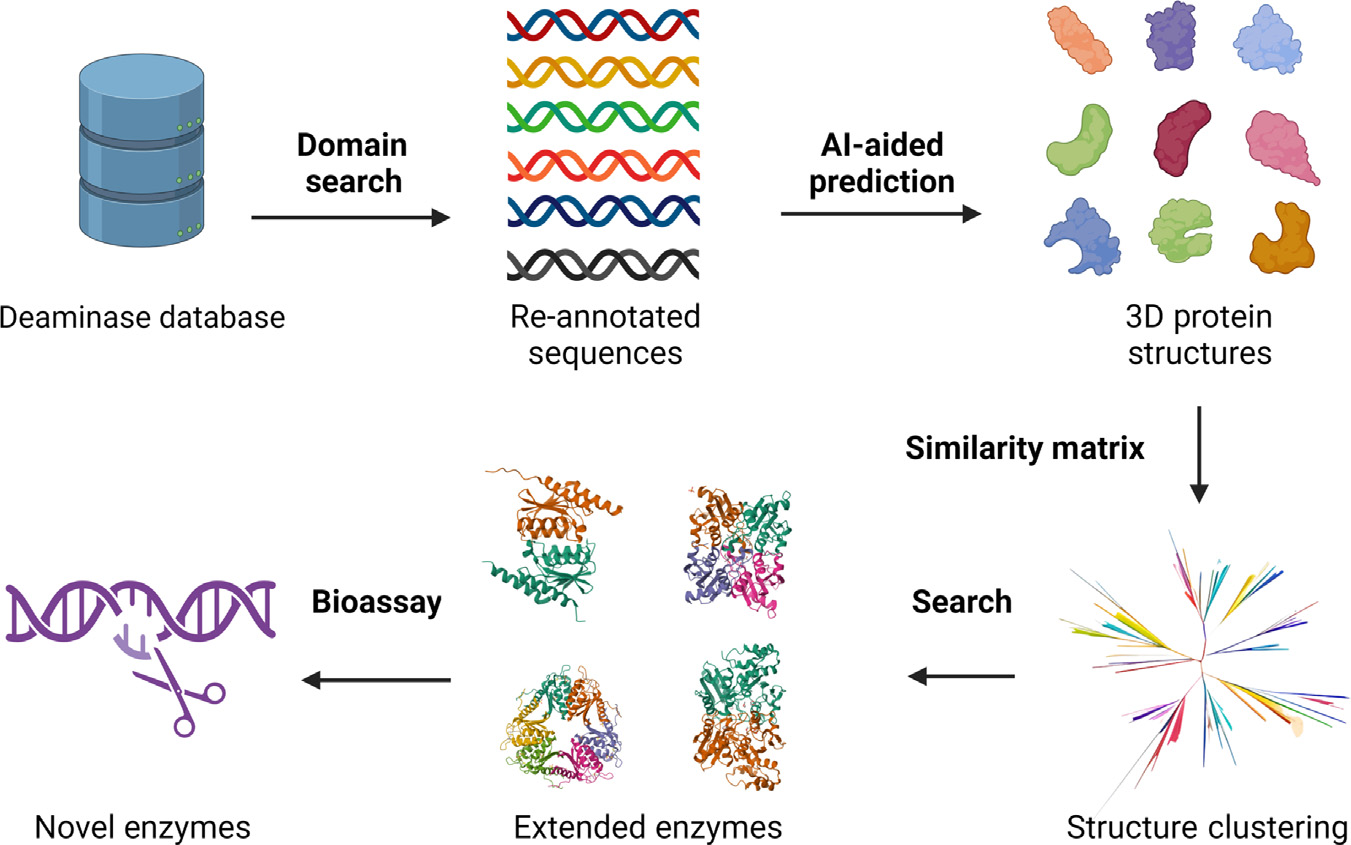
用户发布的文档
加载速度比较慢比较慢,请稍等,手机环境下,有可能无法显示!
" width="100%" height="800">
摘 要
介 绍

实验方法





研究结果






讨论与结论

JACS(IF=15.7)|UCLA团队借力AI+MD解析PfB酶选择性催化机制,4步周环反应高效合成天然产物
Nat.Mach.Intell(IF=23.9)|耶鲁大学:ImmunoStruct多模态AI模型,以26049数据集实现免疫原性预测新高度,AUROC 0.882
Nat.Mach.Intell(IF=23.9)|伯克利国家实验室&密苏里大学开发PoseBench,DL共折叠方法主配体对接成功率64%,突破蛋白-配体对接瓶颈
J.Adv.Res.(IF=13)|AI药物发现新范式:从“微摩尔”到“纳摩尔”,杭州师范大学如何用AI生成+人工优化实现2300倍活性飞跃
APSB(IF=14.6)|中山大学团队构建全球首个萜类化合物生物活性图谱与AI发现平台,精准预测并实验验证新型抗黑色素瘤先导化合物
APSB(IF=14.6)|中国海洋大学+中科院团队利用AI+冷冻电镜,设计出靶向α7 nAChR的最小化芋螺肽,效力提升29倍
Nat.Commun.(IF=15.7)|UBC团队开发强化学习神器TARSA:高效筛选3600万肽库,解锁15种抗乳腺癌活性肽,3种具临床转化潜力
Nat.Commun.(IF=15.7)|香港中文大学(深圳)开发SCOPE-DTI,数据集扩大100倍,AI+3D结构助力药物靶点预测成功率超80%
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1526


Best Last Month
Computer software and hardware
by wittx

Information industry
by wittx

Information industry
by wittx

Computer software and hardware
by wittx
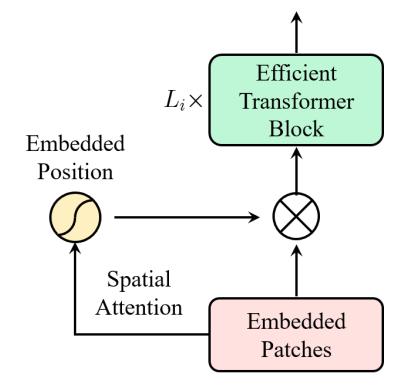
Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond
.jpg)
Computer software and hardware
by wittx

Information industry
by wittx
Information industry
by wittx
Information industry
by wittx
Information industry
by wittx