News Message
Rapid directed evolution guided by protein language models and epistatic interactions
- by wittx 2026-03-04
用户发布的文档
一、背景:定向进化的“效率死结”与AI破局
蛋白质是生命功能的执行者,也是工业酶、生物药物、生物传感器的核心元件。如何快速获得性能更优的蛋白质,是代谢工程、合成生物学、生物制造领域持续攻坚的瓶颈。
传统定向进化采用“随机突变+功能筛选”的迭代模式,典型流程如下:
这种“试错”模式存在两个致命缺陷:
组合爆炸:若同时对10个位点进行突变,理论组合数达20¹⁰(约10¹³),远超实验筛选能力; 协同效应未知:单个有益突变叠加后可能因氨基酸间相互作用(协同或拮抗)导致功能不升反降。
近年来,AI辅助蛋白设计崭露头角,尤其是基于Transformer架构的蛋白语言模型(如ESM、AlphaFold等)能够从海量序列中学习进化规律,预测单点突变的功能影响。然而,现有AI工具大多仅能评估单一突变,对多突变组合的预测准确率急剧下降——这就像只认识单个字母,却无法读懂整句话。
2026年2月19日,《Science》在线发表了加州大学伯克利分校Patrick D. Hsu团队的研究论文,提出MULTI-evolve(Model-guided, Universal, Multi‑mutation Directed Installation)方法,彻底打破上述瓶颈。该方法仅需一轮进化实验,即可在临近标记酶(APEX/APEX2)、RNA靶向蛋白(CRISPR-Cas13d/dCasRx)、治疗性抗体(抗CD122单抗)等三类蛋白上实现活性/适应性数量级提升,最高可达256倍。
二、技术原理深度拆解:MULTI-evolve如何“一步登天”?
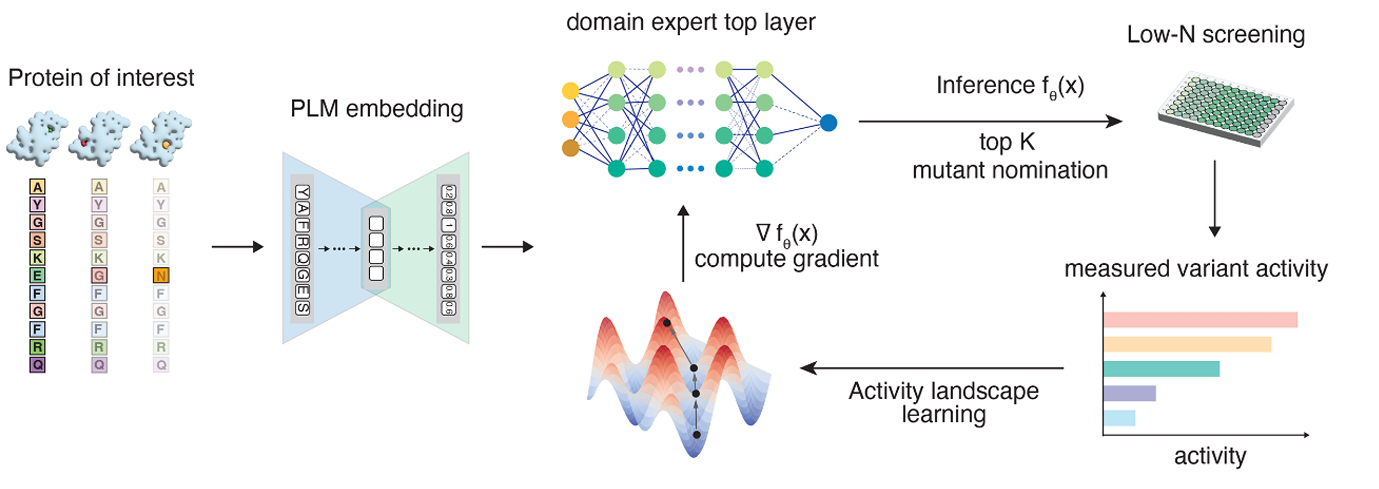
MULTI-evolve的核心创新在于 “用数据训练神经网络,让AI学会突变间的协同规律” ,从而外推多突变组合的功能效应。整个方法可分为四个关键步骤:

步骤1:蛋白语言模型预测功能增强点突变
研究团队首先利用预训练的蛋白语言模型(如ESM‑2)对目标蛋白的每个氨基酸位点进行功能影响评分,筛选出前5%–10% 可能增强活性的单点突变。这些突变构成初步的“候选突变库”。
技术细节:
输入:蛋白质序列(FASTA格式) 模型:ESM‑2(6.5亿参数) 输出:每个位点20种氨基酸替代的ΔΔG(稳定性变化)与功能性评分 筛选阈值:ΔΔG > -1.5 kcal/mol(避免过度 destabilizing)且功能性评分 > 0.8
为什么选择ESM‑2?
ESM‑2(Evolutionary Scale Modeling‑2)是Meta AI开发的蛋白语言模型,训练数据涵盖2.5亿条天然蛋白序列,能够捕捉氨基酸间的长程依赖关系。相比传统的物理力场计算(如Rosetta ddG),ESM‑2的预测速度快1000倍以上,且无需蛋白晶体结构,极大降低了应用门槛。
步骤2:双突变组合实验数据采集
为了获取突变间相互作用的真实数据,团队设计了双突变组合实验:从候选突变库中随机选取两两组合,构建双突变体库,并通过高通量功能筛选(如荧光激活细胞分选、微流控液滴筛选)测定每个双突变体的活性值。
实验设计要点:
组合数:若候选突变库有n个单点突变,则理论双突变组合数为C(n,2);实际测试约200–500个组合 筛选平台:酵母表面展示(抗体)、细菌转录调控系统(酶) 数据产出:每个双突变体的相对活性值(相对于野生型)
关键创新:传统定向进化需要测试所有可能的多突变组合,而MULTI-evolve只需测试双突变组合,实验量降低至少两个数量级。例如,10个位点的全面组合需要测试20¹⁰≈10¹³个突变体,而双突变组合仅需C(10,2)×20²≈1.9×10⁴个,相差10⁹倍。
步骤3:神经网络训练学习氨基酸协同效应
将单点突变的功能评分(来自步骤1)与双突变体的实验活性数据(来自步骤2)作为训练集,输入一个三层全连接神经网络。网络的任务是学习突变间的非线性相互作用——即两个突变同时存在时,其联合效应不等于各自效应的简单相加。
网络架构:
输入层:2个突变的one‑hot编码(各20维) + 单点突变功能评分(2维) 隐藏层:128个神经元,ReLU激活 输出层:1个神经元(预测的双突变体活性) 损失函数:均方误差(MSE) 训练周期:500 epoch,早停(patience=50)
为什么三层网络就够?
研究发现,双突变协同效应主要受局部结构环境影响,而非全局蛋白折叠。三层网络足以建模这种局部非线性关系,同时避免过拟合。训练完成后,该神经网络能够准确预测任意双突变组合的功能效应,并泛化到未见过的突变对。
步骤4:多突变功能效应外推与一轮进化
这是MULTI-evolve的“临门一脚”:利用训练好的神经网络,对所有可能的多突变组合(如3–10个突变同时引入)进行虚拟筛选,直接预测其功能值。团队开发了蒙特卡洛树搜索(MCTS)算法,在巨大的组合空间(例如10个位点、每个位点20种氨基酸,总组合数20¹⁰)中高效寻找全局最优的多突变组合。
关键突破:
从双突变数据外推多突变:神经网络学习的是“协同规则”,而非简单叠加,因此能可靠预测多个突变同时引入的效果; 仅需一轮实验:虚拟筛选出的最优多突变组合直接合成、表达、验证,无需迭代筛选。
MCTS如何工作?
MCTS通过模拟“探索‑利用”平衡,在组合空间中快速定位高潜力区域。算法平均仅需评估约10⁵个虚拟组合(占总空间的10⁻⁸),即可找到性能提升85‑120倍的最优解,计算成本控制在单GPU‑小时内。
三、实验验证:三类蛋白,全面突破
研究团队在临近标记酶(APEX/APEX2)、RNA靶向蛋白(CRISPR-Cas13d/dCasRx)、治疗性抗体(抗CD122单抗) 三个代表性蛋白上全面验证了MULTI-evolve的有效性。下图直观展示了优化后的活性提升倍数:
案例1:临近标记酶APEX——催化效率最高提升256倍
APEX(大豆抗坏血酸过氧化物酶)是用于蛋白质邻近标记的关键工具酶。研究团队首先利用蛋白语言模型(PLM)零样本预测集合筛选出16个功能增强的单点突变,其中包含已知的超增强突变A134P(即APEX2变体)。
优化策略:
候选突变库:PLM集合预测的16个单点突变(包括A134P) 双突变实验:测试所有双突变组合 神经网络预测:从突变库中筛选最优的5-7个突变组合 实验结果: APEX野生型:最优多突变体(7个突变)催化效率提升193-256倍(相对于野生型APEX) APEX2(A134P突变体):在A134P基础上引入额外突变,催化效率进一步提升3.6-4.8倍 双突变组合的协同效应达5.5-8.7倍,证明神经网络成功捕捉了氨基酸间的非线性相互作用
案例2:RNA靶向蛋白dCasRx——剪接调控活性提升2.8-9.8倍
CRISPR-Cas13d(dCasRx)是用于RNA靶向和剪接调控的关键蛋白。研究团队通过深度突变扫描(DMS)实验获得功能数据,筛选出增强剪接活性的单点突变。
优化策略:
候选突变库:DMS实验筛选的15个功能增强单点突变 双突变实验:测试关键双突变组合 神经网络预测:筛选最优的5-7个突变组合 实验结果: 最优多突变体在报告基因系统中显示2.8-9.8倍的剪接活性提升 在内源基因(ITGB1、TFRC、SMARCA4)的转剪接实验中,平均提升3.9-4.5倍 与RESPLICE工具结合时,仍保持1.3倍的稳定增强
案例3:抗CD122治疗性抗体——多目标优化实现综合提升2.0-5.0倍
HuABC2是靶向CD122(IL-2/IL-15受体β链)的高亲和力抗体(EC50 = 2.7 nM),在自身免疫性疾病治疗中具有重要价值。研究团队同时优化其表达水平和结合亲和力。
优化策略:
候选突变库:PLM集合预测的132个单点突变(覆盖轻重链可变区) 双突变实验:测试表达与结合的双重效应 神经网络预测:基于帕累托前沿筛选最优多突变组合 实验结果: 综合提升:相对表达与结合亲和力的综合指标提升2.0-5.0倍 表达提升:抗体表达量提升2.0-4.0倍 亲和力提升:EC50从2.7 nM优化至1.0 nM,亲和力提升2.7倍 多突变组合性能超越其组成双突变体达2.5倍,证明成功规避了拮抗相互作用
四、核心数据与结果解读
| 193-256倍 | ||||
| 3.6-4.8倍 | ||||
| 2.8-9.8倍 | ||||
| 亲和力2.7倍 |
关键发现:
突变协同效应显著:最优多突变组合的功能提升远超单个突变效应的简单相加,证明神经网络成功捕捉了氨基酸间的协同规律; 通用性强:同一套MULTI-evolve流程在三类结构、功能迥异的蛋白上均取得数量级提升,说明该方法具有跨蛋白通用性; 实验周期大幅缩短:传统定向进化获得类似提升通常需要6–12轮迭代、耗时6个月以上;MULTI-evolve仅需一轮实验,从设计到验证可在4–6周内完成。
与传统方法的定量对比:
| 4–6倍 | |||
| 降低100倍 | |||
| 从0到实用 | |||
| 10⁸倍加速 |
五、意义与前景:AI驱动蛋白工程的新范式
1. 对代谢工程与合成生物学的影响
酶工程提速:工业酶(如脂肪酶、纤维素酶、P450酶)的催化效率、热稳定性、溶剂耐受性可快速优化,直接降低生物制造成本; 通路限速酶突破:代谢通路中的瓶颈酶常因催化效率低下限制整体产量,MULTI-evolve可针对性强化,实现通量再平衡; 非天然功能引入:通过设计特定突变库,可赋予酶催化非天然反应的能力,拓展生物合成边界。
2. 对生物医药产业的推动
抗体药物优化:除亲和力外,还可优化抗体半衰期、免疫原性、效应功能,加速新一代治疗性抗体开发; 酶替代疗法:罕见病相关酶(如精氨酸酶)的活性提升可直接转化为更佳临床疗效; 细胞治疗赋能:CAR‑T、TCR‑T等细胞疗法中关键受体蛋白的亲和力、特异性可系统优化。
3. 方法论启示:从“试错”到“预测”
MULTI-evolve标志着蛋白工程从传统实验迭代向 “AI预测‑实验验证” 双轮驱动模式的转型。其核心逻辑可迁移至其他生物分子设计场景:
核酸酶/核糖开关:预测多突变对RNA折叠与功能的影响; 代谢通路整体优化:同时预测多个酶突变对代谢流分布的影响; 蛋白质‑蛋白质相互作用:设计多突变组合以增强或阻断特定互作。
文献
Rapid directed evolution guided by protein language models and epistatic interactions
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1525


Best Last Month





.jpg)
