News Message
Automatic Prompt Optimization with “Gradient Descent” and Beam Search
- by wittx 2023-07-15
用户发布的文档
加载速度比较慢比较慢,请稍等,手机环境下,有可能无法显示!
" width="100%" height="800">
请输入您的信息!
Share Http URL: http://www.wittx.cn/get_news_message.do?new_id=1210


Best Last Month
Information industry
by wittx

Information industry
by wittx
Information industry
by wittx
Computer software and hardware
by wittx

Information industry
by wittx
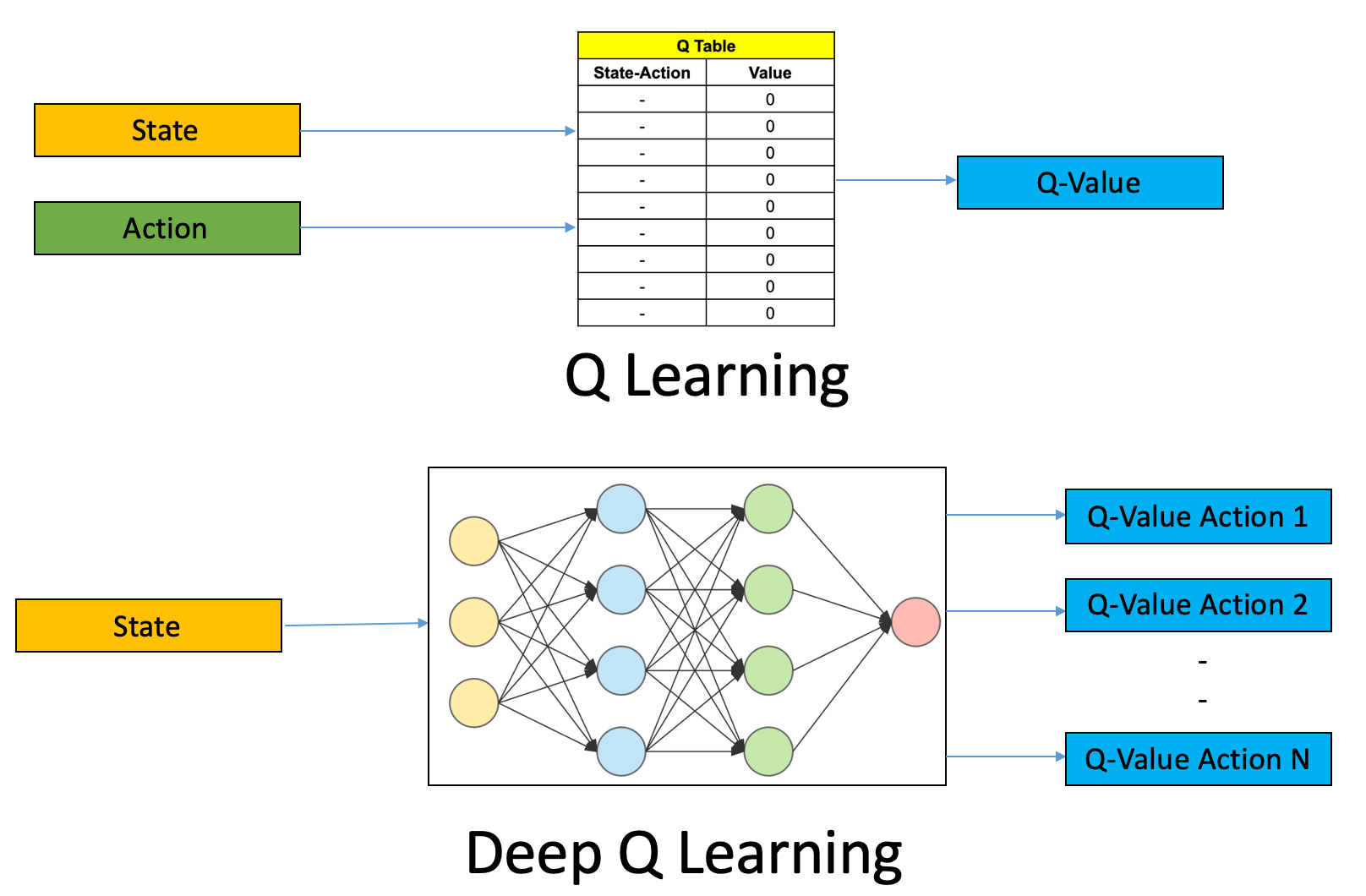
Challenges in the Verification of Reinforcement Learning Algorithms
Information industry
by wittx
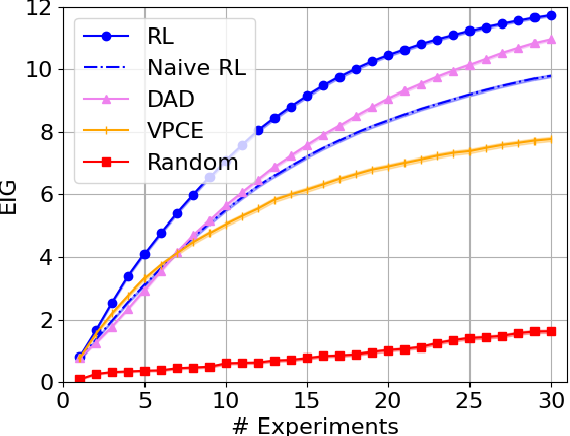
Optimizing Sequential Experimental Design with Deep Reinforcement Learning
Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models
Information industry
by wittx